![[EP -10] The Magic Behind Blockchain: ⇛ Directed Acyclic Graphs ⇚](/_next/image?url=https%3A%2F%2Fuploads-ssl.webflow.com%2F660e449a26dad71301a18f76%2F66310c0df5faaa2a7042828c_6630c221bcad1d7f4a07c0cd_63d2c94b125a1be515fbf27a_1_Xnq3WViouFgOABhyQKMwvQ.png&w=3840&q=75)
🎉Congratulations and thank you to all who have made it to this episode!🥳 Episode 10 is such a monumental achievement for us all. Before we go into our topic for today, let’s take a quick summary of how far we have come.
BIG 10 RECAP
- In Episode 1, we understood the power of decisions and why I call the so called Blockchain, a Distributed Decision Technology (DDT). We also looked at Consensus (the heart of DDT) and the Scalability of Trust problem.
- In Episode 2, we looked at a homegrown blockchain solution and some typical consensus attack vectors namely (Participant selection and Value correctness). This was a foreshadow to the actual application of these attacks.
- In Episode 3 and Episode 4, we created a framework that encapsulates the basic variables that make up any blockchain. This consists of the Byzantine Generals’ Problem, CAP Theorem, Blockchain Trilemma, Consensus Categorisations, the blockchain architecture, and others. This one image / framework gave a holistic picture of any blockchain solution. We will take a practical example of how to use this in future episodes.
- In Episode 5, we understood exactly what consensus algorithms are and how to create them (Spoiler: They are not exactly found in nature). We further harmonised over 80 consensus protocols and decomposed them into 4 main categories (Economic Cost-Based, Capacity-consuming, Gossip-Based and Hybrid protocols).
- In Episode 6, Episode 7, Episode 8 and Episode 9, we built a deeper layer on the first 5 episodes by delving into Byzantine Fault Tolerance Algorithms — a particularly efficient set of consensus algorithms. We made comparisons (speed, complexity, security, safety and liveness) between Classical, Practical and Delegated (v1 and v2) BFTs.
Today we will look at Directed Acyclic Graphs (DAGs) as used in consensus applications — a truly powerful technology capable of very high transaction speeds. We will try to understand why DAGs are needed, what they are, how they work and some pros and cons of using DAGs. So sit back, relax and let’s dive in.
Why do we need Directed Acyclic Graphs (DAGs)?
There are two hidden drawbacks of most of the consensus algorithms we discussed so far in previous episodes. I have purposely avoided mentioning these drawbacks until it was truly worth mentioning. Now the time is right. They are:
- Consensus Incentive and Inability to support micropayments: Most consensus algorithms provide some sort of reward for consensus participants (depending on the technology sometimes called miners, validators, minters, voters, consensus committee, etc.). This is essential economics to keep the system running as intended. Cryptography (hashes, encryptions, signatures, etc.) will not last forever. Eventually, as time goes on, most will get broken. What lasts a lifetime is the need for humans to do what is in their own self-interests. So incentives are a necessary part of a blockchain if you expect it to run long term. Most consensus rewards are created either from thin air (e.g. Bitcoin rewards) or from some sort of transaction fee.
Transaction fees inadvertently places a financial limit on how small transaction can be. Let’s say you need to purchase a pin for 1 cent using Bitcoin, you would most likely end up paying transaction fees larger than the cost of the pin. This makes most types of blockchains impractical for smaller transactions (micropayments). Of course there are tools like Payment Channels, however, this is a workaround rather than an intentional / in-built design choice.
2. Heterogeneous Consensus: Most blockchain consensus protocols have a distinct transaction issuer and transaction approver (user vs miner, account vs validator, primary vs delegate, etc.). The inherent reason why it is designed like this is prevent conflicts of interest. Clearly, I should NOT be able to approve transactions that I myself created. However, there is another side of this coin.
This kind of system with distinct issuer and approver creates unavoidable discrimination. These two must be treated differently and many times the discriminatory operations result in conflicts that usually require extra resources to resolve.
3. Blocks and Limits: This whole idea of blocks introduces a rather interesting problem. For example: Bitcoin and Litecoin have a block size of 1mb, Bitcoin Cash has a block size of 32mb. Immediately you have a fixed block size, this design choice also forces a limit in the number of transactions. If you start limiting thenumber of transactions, you also then inadvertently introduce a limit in growth of the entire blockchain. Let’s say you even avoid this problem like in Ethereum (Ethereum block size is not fixed but depends on gas limit), eventually you run into a problem where it becomes very difficult to propagate large size blocks throughout the network. Now you have to waste resources on extending chains, sharding, etc.
The three reasons (and others) above are some of the core problems DAGs try to resolve.
What exactly are DAGs?
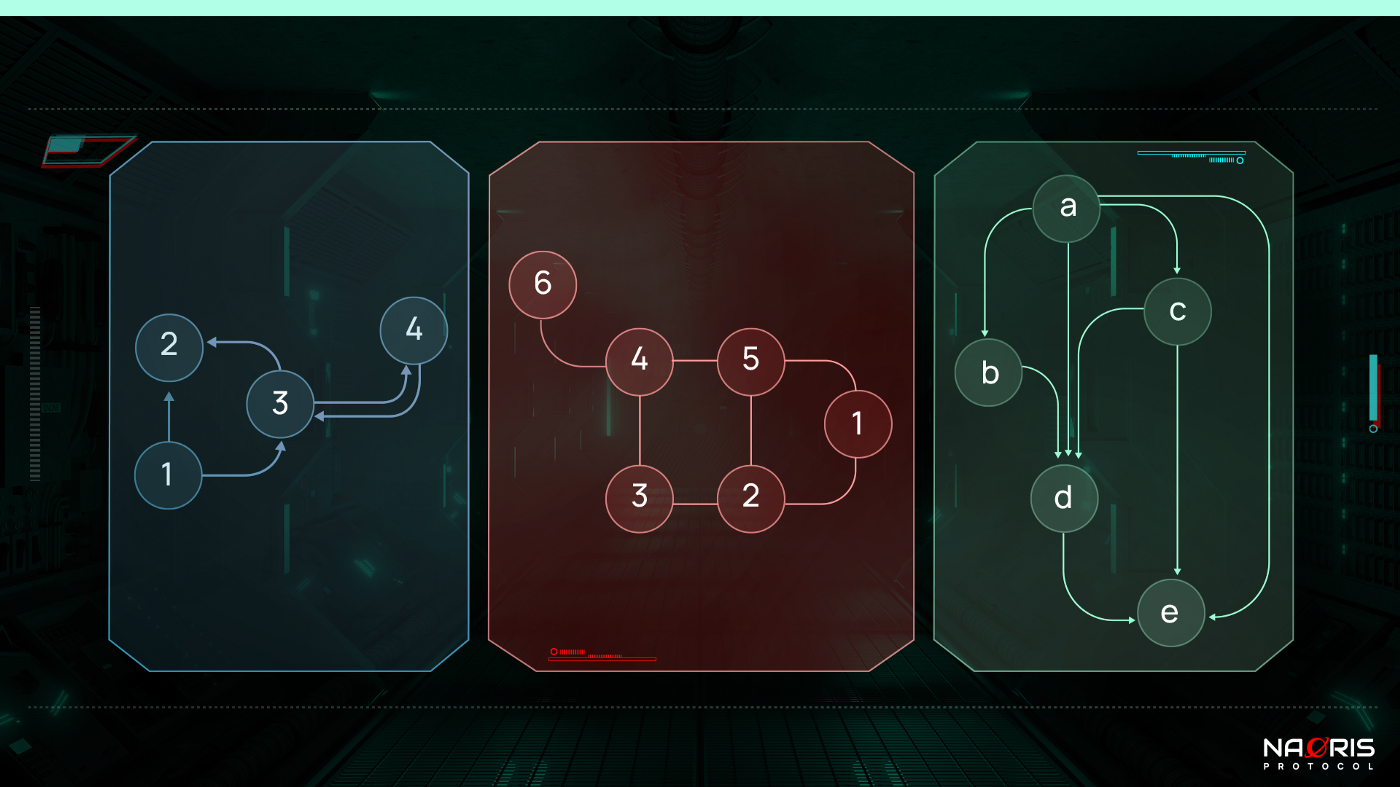
Our universe is filled with objects. These objects usually interact with one another in some way. One way to visualize such connections in Mathematics is using graphs.
Figure 1 above shows 3 graphs (blue, red and green). A graph is simply a mathematical figure that consists of multiple pairs of objects that have a relationship between them. For example: the blue graph on the left has 4 objects (1, 2, 3 and 4). These objects are usually called vertices / nodes. The same graph can also be said to have 4 pairs (1,2) (1,3) (2,3) (3,4). The pairs just show the possible relationships that could exist between objects / vertices. The relationship is usually denoted by a line (called an edge).
If the relationship flows in a particular direction, this line becomes an arrow (so it has a direction hence the word Directed). A graph with such directed edges is called a Directed Graph such as the blue graph on the left ( its arrows are sometimes called an arcs). Conversely, the red graph in the middle has no directional flow of relationship between the objects, hence, this is an Undirected Graph.
Sometimes Directed Graphs will form a closed chain or cycle between the objects / vertices. Thus, the relationship moves from one object to others and eventually returns to the initial object. For example, the blue Directed Graph has a cycle between vertices 1, 2 and 3. This is called a Directed Cyclic Graph (or Cycle Graph / Circular Graph/ Cyclic Graph). Often the word “directed” is dropped because of redundancy. If you don’t have any direction in the first place, how can you form cycles?
The green graph on the right shows a graph in which the arcs (edges) form NO closed chain or cycles. Hence the name Directed Acyclic Graph (DAG). Now you know exactly what a DAG is, therefore, I will leave you to conjure a definition.
How does a DAG-based Consensus work?
The usage of DAGs for consensus were popularised mainly by the IOTA distributed ledger and others like Obyte (former ByteBall), Dagcoin, Swirlds, etc. For IOTA, the main goal was to solve the Consensus Incentive and Hetegeneous consensus problems we discussed above. They also wanted to utilise this Distributed Ledger technology efficiently for IoT systems (limited microchips not a lot of memory / processing power which usually also utilise a lot of micropayments). They called their solution the Tangle. I guess the word mesh / graph seemed too obvious 😊.
It should be noted that the IOTA team does not consider the Tangle as a Blockchain solution; and they are technically right. If you read Episode 1, you know exactly why I agree with this. The Tangle does not have a singly-linked list as the data structure on the content-layer like Bitcoin. It is technically not a chain of blocks. However, the Tangle is still used to achieve consensus, therefore it is a Distributed Decision / Ledger Technology. Now you understand why I kept saying so-called Blockchain in Episode 1.
Site Set VS Edge Set
Tangle takes advantage of the phrase— “love your neighbour as yourself”. But in IOTA DAGs, you need to love your neighbour twice as much as you love yourself. To issue a transaction, you must approve two other unconfirmed transactions. This is simply because, at the point of issuing / creating a transaction, the user has enough incentive for their transaction to go right. Hence, they will willingly work to approve 2 other transactions. Other nodes will also do unto you as you have done for them. And this is how you will also get your transaction approved.
There is a perfect symbiosis! Your approval is in some ways the fee for your transaction but you are paying in kind instead of money, token or gas. Other DAG technologies like Obyte, etc have different incentivizing schemes although the DAG data structure remains the same.
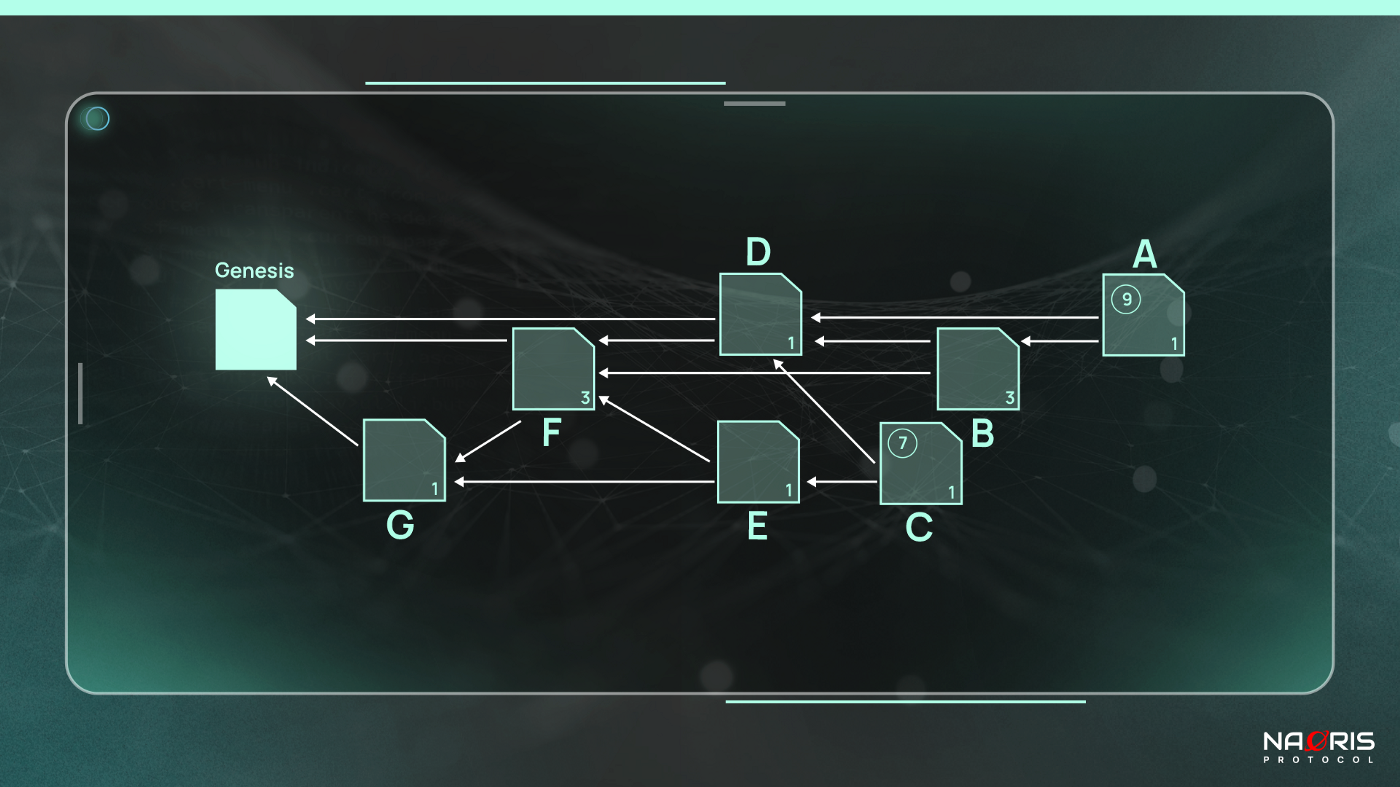
In a Tangle, instead of a chain of blocks (like a regular blockchain), transactions are represented by the vertices (in Figure 2 above; the squares) on the DAG. Each transaction is its own block!
Each vertex represents a single transaction containing a hash, value and digital signature. If you consider that all the transactions on the DAG (in the Figure 2 {A, B, C, D, D, F, G}) represent a set of all vertices (also called sites) on the DAG, then the actual ledger that stores the transactions is a set of sites (vertices), hence, the name site set.
Note that time moves from left to right in a DAG so newest transactions can be found on the right. The oldest transaction, like the Genesis transaction, can be found on the leftmost part.
What do the arrows (edges) represent? We can guess that they represent is the relationship between transactions. The set of all arrows (edges) are usually called an edge set. So how exactly do we achieve the arrows (edge set)?
When a new transaction (e.g. in Figure 2, transaction A) arrives, it must approve two previous transactions (transactions B and D). This is a Direct Approval. Therefore the exact relationship each arrow in the edge set represents is an approval / confirmation.
On the other hand, if you have two transactions (e.g. in Figure 2, C and F), and there is no immediate arrow (directed edge) between them, but rather a path from C to F going through at least one block, thus block E. (path length is at least 2: so 2 arrows in the path), then we conclude that C indirectly approves F.
The first transaction is called a “genesis transaction”. However, unlike the “genesis block” in regular blockchains, the genesis transaction contains all the tokens (monetary value) that will ever be present in the entire DAG / Tangle. These tokens are usually sent to “founder” addresses. No further mining of transactions will occur so no further token rewards will be given from “thin air”. This is very different from Bitcoin where the system gives miners tokens from thin air. Of course there is a limit in code of the total bitcoins in circulation, thus 20million. However, the difference is that all these 20million coins are never contained in one wallet in their lifetime.
In conclusion, the basic premise here is that: In DAGs, to issue a transaction, users must work to approve other transactions. So users can be both issuers and approvers simultaneously. And users who issue a transaction somehow automatically contribute to network security by approving others’ transactions. If a node finds a transaction that conflicts with the Tangle history, it will NOT approve the conflicting transaction. The result is that transactions receiving more approval are accepted with a higher level of confidence. It eventually becomes difficult to make the system accept double-spending transactions with high confidence.
Transaction Issuing and Approval Process
To put things in perspective, let’s look at how a typical transaction is issued:
1. A node creates their transaction but to issue this transaction, they choose two other unconfirmed transactions to approve according to an algorithm. These are usually tip transactions.
And oh, a tip is just a transaction that has NOT yet been approved
Note that there is no specific set of rules (algorithm) for choosing these two transactions. However, if a node sees that a majority of nodes are following some rule (reference rule), it is always better for them to stick to the same rule.
2. The issuing node ensures that the two transactions are not conflicting with each other and also that the two transactions do not conflict with any other existing transactions in the Tangle history.
3. Then the node runs an algorithm to find a nonce such that, the found nonce concatenated with with data from the approved transactions has a particular form (eg. leading zeros). This step is quite similar to the Bitcoin Proof of Work (PoW) concept we saw in Episode 5.
Note that Tangle allows conflicting transactions to co-exist with valid transactions. Nodes do NOT necessarily have to achieve consensus on which a transaction is valid and have the right to be on the ledger.
However, for conflicting transactions, nodes decide which transactions become orphaned by running a Tip Selection Algorithm (random or otherwise) many times. The main purpose of this Tip Selection Algorithm is that, given two transactions that conflict with each other, it determines which transaction is more likely to be indirectly approved by a selected tip.
So for example given two transactions A and B where A is valid and B is conflicting. If you run the Tip Selection Algorithm 100 times and A is selected 97 times, we say Transaction A is confirmed with 97% confidence.
4. Issuing node signs the transaction using their private key and broadcasts it to the network.
5. Other nodes in the network verify the transaction and add the transaction as the new tip in their copy of the DAG.
6. The transaction waits for direct and indirect approvals by new transactions. This updates the new transaction’s cumulative weight.
7. If cumulative weight is larger than some threshold value, the transaction is then considered confirmed.
Weight, Height, Depth and Score
In Figure 2 above, did you ask yourself: “what are the numbers written in the vertices?” These are the weights (own weights) and cumulative weights.
The weight (own weight) of a transaction is just the amount of work the issuing node invested into it. So the computational work required to build a transaction (block / vertex). In IOTA the weight of transaction can only be a power of 3. So it must be of the form 3ⁿ where n is is a positive integer. Every transaction must have a positive integer weight (so 3⁰ = 1, 3¹ = 3, 3² = 9, etc.).
In general, a transaction with higher weight means more computational work has gone into it, therefore, it is more important than a lower weighted transaction. The assumption is that, it is very improbable for an entity to generate a large number of transactions with weights that are large enough to be considered “acceptable” by other nodes.
The cumulative weight of a transaction is the summation of the transaction’s own weight and the weight of all other transactions that directly or indirectly approve it.
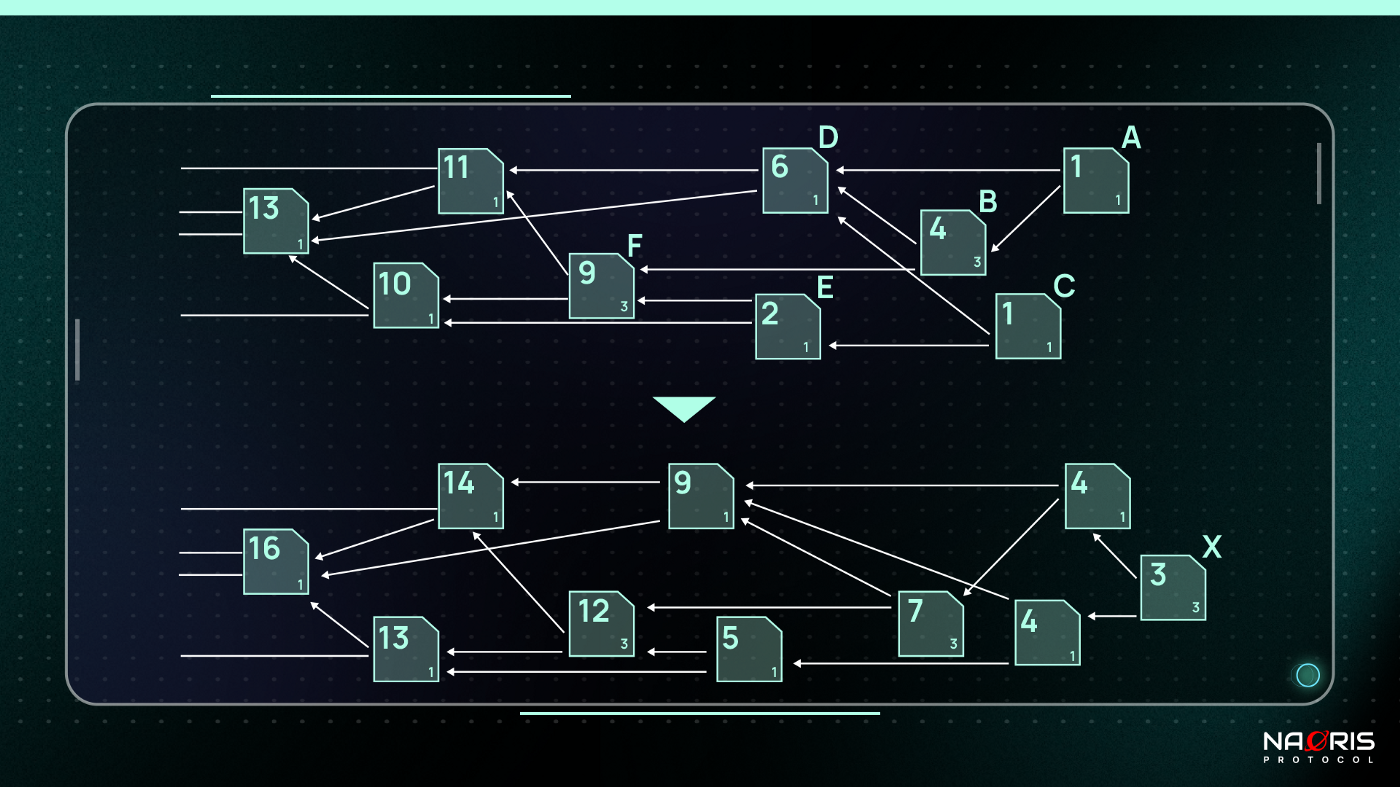
Let’s put things in perspective. In Figure 3 above, we see the tangle at the top consisting of transactions A, B, C, D, E and F. At the bottom we see the changes that occur in the DAG after a new transaction X is issued.
At the bottom right corner of each transaction, you see the own weights of the transactions. They are all either 1 or 3, so powers of 3 (3⁰ = 1, 3¹ = 3). The numbers written in larger font on the transactions represent the cumulative weights of the transactions. For example: the cumulative weight of transaction F is 9. F is directly approved by transactions B and E and indirectly approved by transactions A and C. Therefore, the cumulative weight of F is the sum of F’s own weight (3) and the own weights of transactions (A, B, C and E) = 3 + 1 + 3 + 1 + 1 = 9. This is how we get the number 9. You can work out the other cumulative weights to test your understanding.
Transactions A and C are clear tips because their cumulative weight (1) is equal to their own weight (1), so clearly no other transactions have approved them. On the bottom DAG / tangle, when transaction X is issued, X suddenly becomes the only tip. Its own weight is 3 which is equal to its cumulative weight so still no approvals. By logical conclusion, X will directly approve transactions A and C making their cumulative weights 4 (3 + 1), and indirectly approve all other transactions effectively increasing their cumulative weights by 3 each.
If you count the longest oriented path (number of arrows towards the genesis) from a given transaction to the genesis transaction, this is called the height of transaction in the DAG. Similarly, if you count the longest reverse oriented path (number of arrows away from the genesis) from a given transaction to some tip, this is called the depth of the transaction in the DAG.
For example, in Figure 2, G has a height of 1(longest path to genesis block is 1) and depth of 4 (longest path to tip through F → D → B → A). Similarly D has a height of 3 and a depth of 2.
The last notion to understand is the concept of score. A score is quite similar to cumulative weight. While cumulative weight looks at the sum of own weights of transactions that have approved (directly or indirectly) a chosen transaction say X, including the transaction’s own weight, score looks at the sum of own weights of transactions X itself has approved (including X’s own weight). So for example: In Figure 2, if you consider the tips A and C, you will notice that transaction A directly or indirectly approves transactions B,D,F and G so it’s score is 1 + 3 + 1 + 3 + 1 = 9. Similarly the score of C is 1 + 1 + 1 + 3 + 1 = 7.
System Stability, Cutsets and Weight Growth
A DAG environment is usually random and may be statistically analyzed, however, it is difficult to precisely predict which transactions will be confirmed and which ones will NOT be confirmed. Such an environment can be characterized as a stochastic system.
If we assume that T is the set of all tips in a particular tangle / DAG;
where T = {t₁, t₂, t₃, t₄, …, tₙ} and |T|ₜ = total number of tips in the system at any given time t,
One would expect that this stochastic system is stable. Here, stability means that: as the DAG grows, the total number of tips at any point should be finite (not infinite). In mathematical terms:
lim (|T|ₜ) as t → ∞ = k where k ≥ 1 and k is a positive integer
So as the time (t) approaches infinity, the tips (unapproved transactions) should remain a finite number k. If this is not true, then it means there will be an infinite amount tips as the DAG grows with time; meaning many unapproved transaction would just be left behind. No one wants an environment where transactions are not being confirmed possibly forever. Stability is, therefore, crucial for DAGs! Unapproved transactions and unattended tips means that consensus is not reached on many transactions.
Therefore, this leads us to a very important question:
How long does it take a tip to get its first approval?
Before answering this question, we need to first distinguish between two types of tangles that may occur.
- Low Load: A tangle with a very small number of tips which usually get approved fast and quickly transforms into a tangle with only 1 tip. This can happen for many reasons. The latency of the network is very low but devices compute fast. This means transactions are circulated slowly and processed very fast so fewer tips would appear. This may also happen especially when the in-flow of transactions (incoming transactions) is very small.
- High Load: A tangle with a very large number of tips. This usually happens when there is a large in-flow of transactions but devices have computational delays and network latency. This means there are many transactions to processes but they are not getting circulated through the network fast enough and devices are taking longer to process them. Eventually there will be a large number of tips (unconfirmed transactions).
Figure 4 below shows High load (higher tangle in the image) vs Low Load tangles (lower tangle in the image)
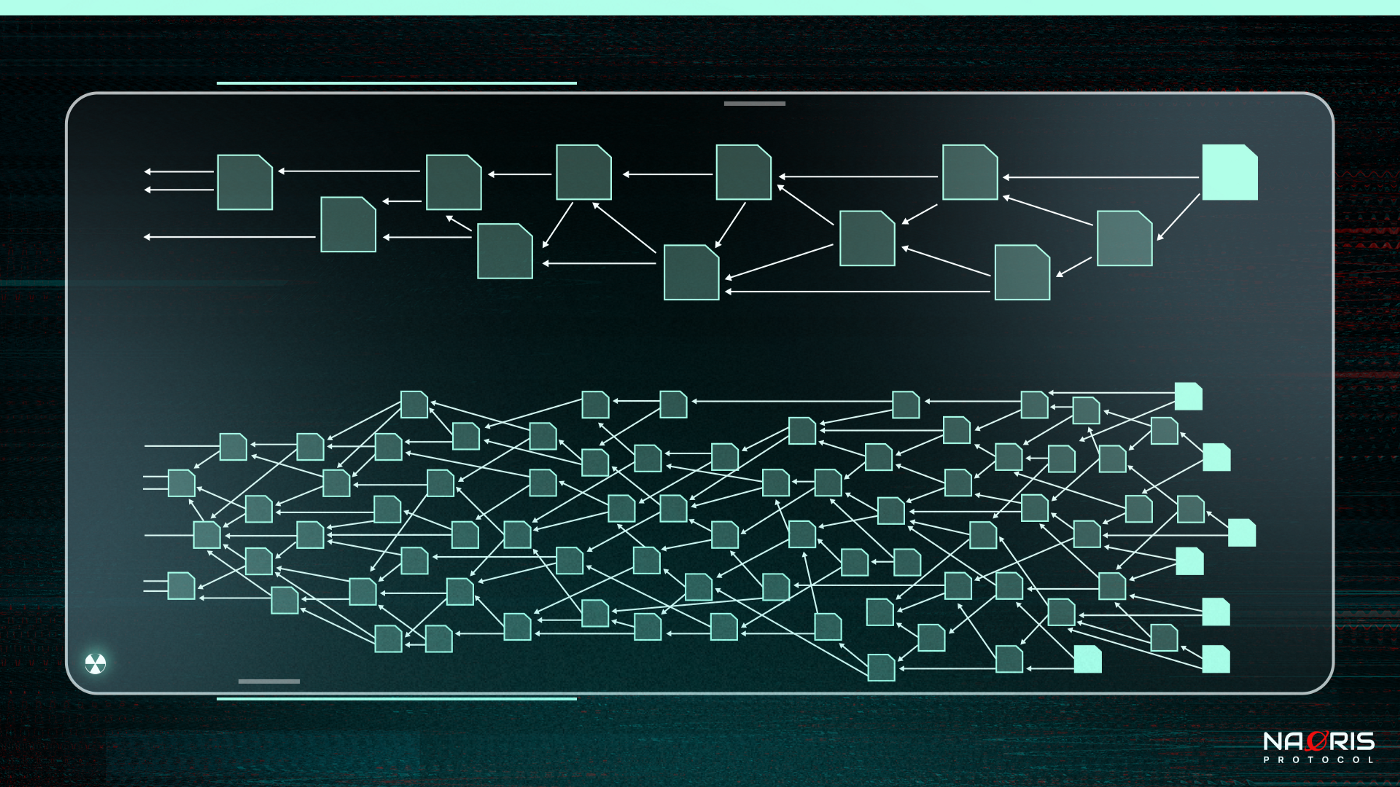
Now back to the question on how long it takes a tip to get its first approval, we need to make the following assumptions:
- Transactions are issued by a large number of somewhat independent entities. This implies some randomness in source and number of incoming transactions. Anytime you have such a situation occurring, where there are random points in some mathematical space, you can model this with a Poisson Point Process. So we then assume that λ as the rate of the Poisson process. We assume new transactions are arriving at a constant rate λ (e.g λ = 3000 transactions per second).
- Let’s also assume that all devices have approximately the same computing power. So we can say h is the average time a device needs to perform the calculations necessary to issue a transaction. (e.g. h = 2seconds).
- Assume that all nodes randomly choose two tips when they want to issue a transaction. This tip selection strategy makes our analysis easy. However, please note this strategy is particularly vulnerable because some nodes may decide to discriminate. Thus, they select only a particular set of tips consistently rather than others. These are called lazy nodes.
- When a node issues a transaction at time t, they don’t observe the state changes of the tangle immediately. It is reasonable to assume that this happens after they have finished their computation. So they can observe the new state of the tangle after t + h when it becomes visible to the entire network. For this to happen, the number of tips must remain stationary in time. So number of tips must roughly fluctuate around the number |T|ₜ ₌ ₀ > 0.
We can now come to the following calculations:
At any given time t, there are roughly λh tips. So a mathematical product of the rate of incoming transactions (λ) and average time taken to issue a transaction (h). But these tips are “hidden tips”. They are not yet visible to the entire network because they were attached between time t - h and t.
We can also assume that there are r “revealed tips” (A subset of tips that are visible to the tangle network at the time).
So we can finally conclude that |T|ₜ ₌ ₀ = r + λh, thus total number of tips in the network is a sum of revealed tips (r) and hidden tips (given by λh)
We can also assume that at time t , the hidden tops (λh sites) were tips at time t — h but are not tips anymore in this very second (time t).
Note that at any fixed time t, the set of transactions which were tips at some moment s ∈ t, [t + h(|T|ₜ ₌ ₀, N)] is called a cutset. Any path from a transaction issued at another time t ‘ > t to the genesis transaction must pass through this cutset. Cutsets can be used as checkpoints for possible DAG prunning and other changes. It is important that new cutsets are of a smaller size.
This means:
If a new transaction comes in now (time t), it has to choose 2 transactions from the “revealed tips” in order to approve them. The probability of selecting a tip is r / (r + λh). The denominator is so because this node can see r tips but there are also λh that although are not tips anymore, the node doesn’t know and still thinks they are tips. So for selecting these two transactions, the mean number of chosen tips become 2r / (r + λh).
Now let’s wrap this up, we already mentioned the assumption that the number of tips is stationary (so it doesn’t change). If we assume that the number of stationary tips = 1 (for low-load tangle), then it means
2r / (r + λh) = 1 ;
r = λh ; solving for r
The above equation is a really important equation because it means the total number of “revealed tips” (visible to the entire tangle system) if we assume a stationary tip is λh.
In less mathematical terms, |T|ₜ ₌ ₀ = 2λh means we can now reasonably predict how many transactions will be visibly unconfirmed (revealed tips) in a tangle at time t = 0 if we know the rate of the transaction inflow and the average computation time a device takes to issue a transaction (confirm 2 other tips). Revealed tips is simple two-times the hidden tips!
You can even generalize the above equation. If a new transaction references / confirms k transactions instead of 2 transactions then your equation would be |T|ₜ ₌ ₀ = kλh / (k — 1). The proof of consistency for this is trivial because if you take the mathematical limits of the above equation as k → ∞, you will get back to λh (still finite).
Now we can finally answer our question. The expected time for a transaction to receive its first approval will be h + (|T|ₜ ₌ ₀ ) / 2 λ = h. For 2 transactions = 2h. So it is obviously the average time it takes to issue a transaction, in addition to the average time it takes for 2 transactions to be visible (To get this we divide total number of tips by twice the rate of an incoming transaction. (Note rate (t/s) = number of tips (t) / time (s)).
If you work this out by substituting |T|ₜ ₌ ₀ = 2λh into [h + (|T|ₜ ₌ ₀ ) / 2 λ], you get 2h. So it roughly takes twice the time for issuing a transaction to approve it. This is important if you are looking at the stability of a DAG. Because this time directly influences the approval strategy which is the heart of a DAG.
Asymptotic Complexity
From this we can also see that in a low-load Tangle, the typical time in which a tip will get approved in O(λ⁻¹) time units where λ is the rate of the incoming flow of transactions.
Conversely in a high-load Tangle, we can deduce that the typical time in a which a tip will get approved is O(h) time units.
Note that if the confirmation for some reason does not occur within these time limits, one can always “promote the transaction” by creating a new empty transaction which approves the previous delayed transaction
Weight Growth
So let’s assume you set up a DAG, you understood the stability principles so you chose the perfect approval strategy that nodes can implement and most importantly, you found a way to incentivize that strategy. The next question to ask is:
“How fast will the cumulative weights of transactions grow”?
The above question is important because, this will directly influence which transactions are chosen as more important than others and again influence the weight threshold at which transactions are considered confirmed. You need to be able dial this in and maintain system stability as the DAG grows!
Assuming that we have a low-load tangle, after a transaction gets approved several times, its cumulative weight will grow with speed λ because all new transactions will indirectly reference this transaction. This is trivial. In practical terms it will grow also taking into consideration the mean weight of a generic transaction (w) so cumulative weight growth will increase by λw.
In a high-load tangle, however, an old transaction with a large cumulative weight will experience weight growth with speed λ again because all new transactions will indirectly reference it. However, when a new transaction is first added to the Tangle, it may have to wait for some time to be approved (because it is High-load). Within this waiting period (time interval), the transaction’s cumulative weight will behave in a random fashion.
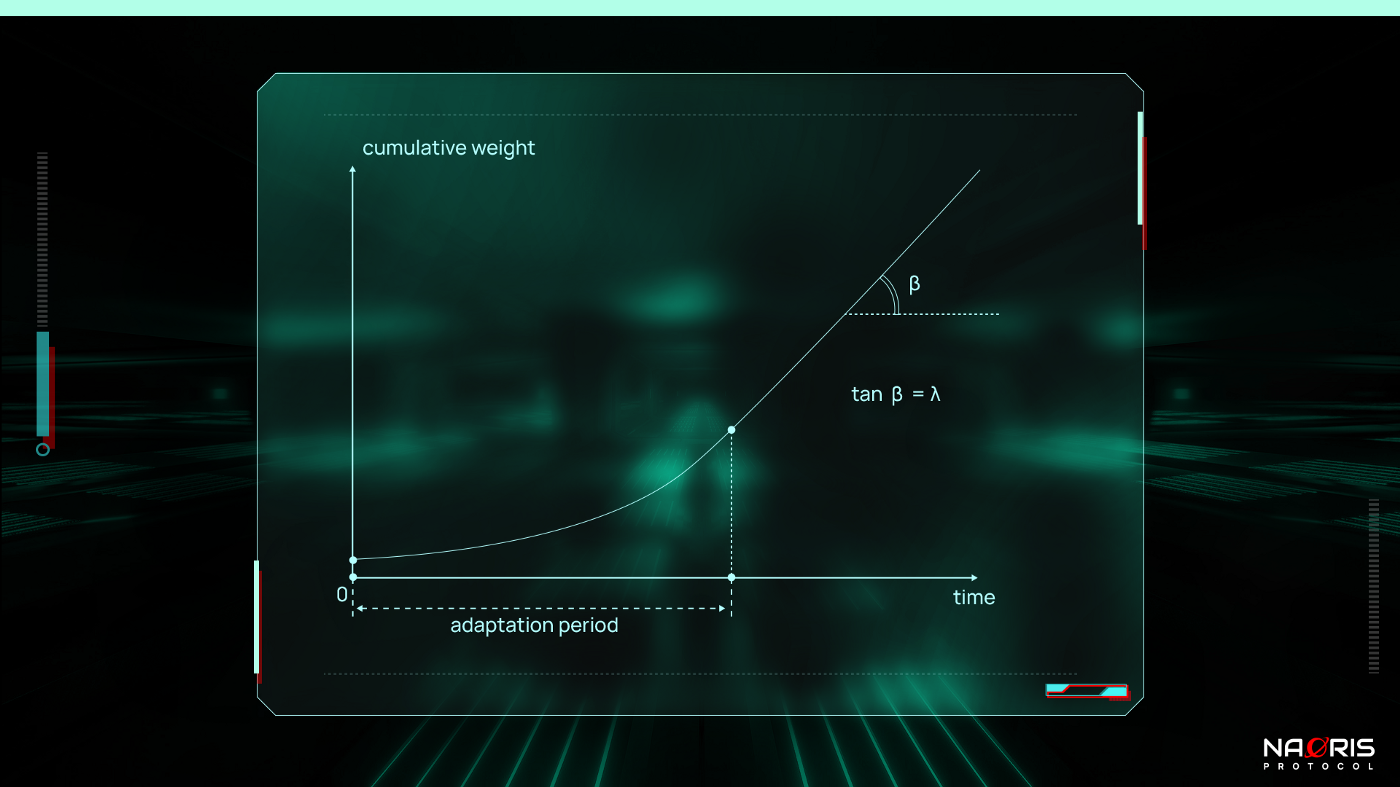
This is an important period. Because every transaction will have this special time period which lasts until most of the current tips have indirectly approved the transaction. This is technically known as the adaptation period. It is mathematically given as:
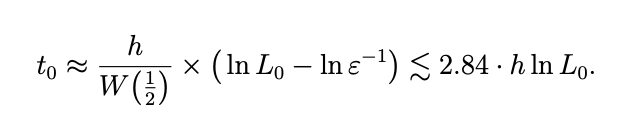
L₀ = |T|ₜ ₌ ₀
It is found that in a high-load tangle, there are two distinct growth phases.
- The first growth phase is the transaction’s cumulative weight growth during the adaptation period. This happens with increasing speed as governed by the equation below:
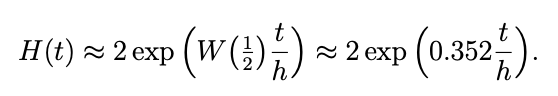
- The second cumulative weight growth happens after the adaptation period. This happens with the speed λw regardless of the approval strategy. It has to of course be a reasonable approval strategy. This second growth rate is shown below in Figure 5:
The mathematical deduction and proof of the above equations are out of scope of this Episode. We may touch on it in more advanced future episodes. For now, Mathematics enthusiasts can see the proof in the IOTA Tangle paper.
Security Attacks
So what are the advantages and the problems that arise when one decides to get rid of the traditional “blockchain” and use a DAG instead?
- Network Outpacing: Network outpacing is a kind of attack in which the attacker conducts a transaction on the network (e.g. sending payment to a merchant), gets the benefit of the transaction off network (merchant sends goods after seeing transaction has sufficiently large cumulative weight), and then quickly tries to roll back the initial transaction (issuing a transaction that spends the already spent funds again (double-spending transaction)) hoping to beat the network transaction finality. This usually takes a lot of computing power. The trick here is not to approve the original transaction. This is called a large weight attack. We saw an example of this in Episode 5 under time agreement problems. How is this possible? The attacker could control multiple nodes under multiple identities (Sybil attack) or using all their computing power. This transaction will therefore had a very large own weight. Using this transaction to approve transactions prior to the legitimate transaction will therefore intentionally giving the legitimate transaction a smaller weight and essentially invalidating it (making it orphaned). The new sub-tangle in essence outpaces the legitimate sub-tangle.
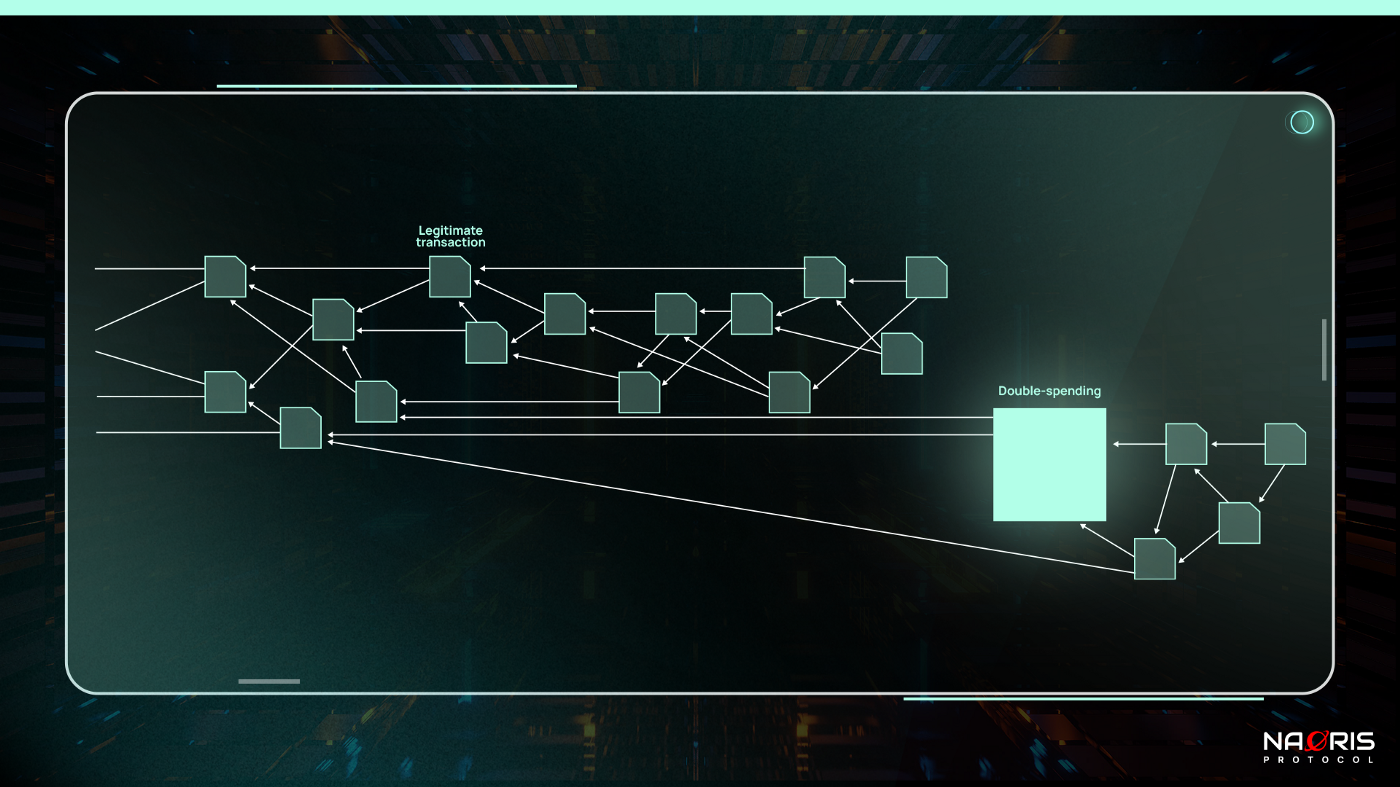
Figure 6 above shows the Large weight attack. One countermeasure to this attack will be to start limiting the own weight of transactions or setting it to a constant value. Setting transaction weights to a constant value may make the system susceptible to spamming.
2. Dependence on Tip Approval Strategy: Tip approval strategy is the most important ingredient for constructing a tangle-based cryptocurrency. It is there that many attack vectors are hiding. Also, since there is usually no way to enforce a particular tip approval strategy, it must be such that the nodes would voluntarily choose to follow it knowing that at least a good proportion of other nodes does so.
Using weights as a decision metric to choose between two conflicting transactions because this weights are subject to attacks. E.g. Attacker may create a secret sub tangle with a double spending transaction (all with good weights) secretly waiting to publish after the merchant accepts the legitimate transaction.
3. Parasite Chain Attack: In this attack, the attacker creates a secret subtangle (side chain) that occasionally confirms / approves / references a transaction on the main chain and eventually gains a higher score. This parasite chain laying dormant can give the attacker the chance to give more height to parasite tips (using a strong computer) or even increase their tip count at the moment of attack by broadcasting many transactions that approve a transaction they issued earlier. This will give the attacker an advantage in the case where the honest nodes use some selection strategy that involves a simple choice between available tips.
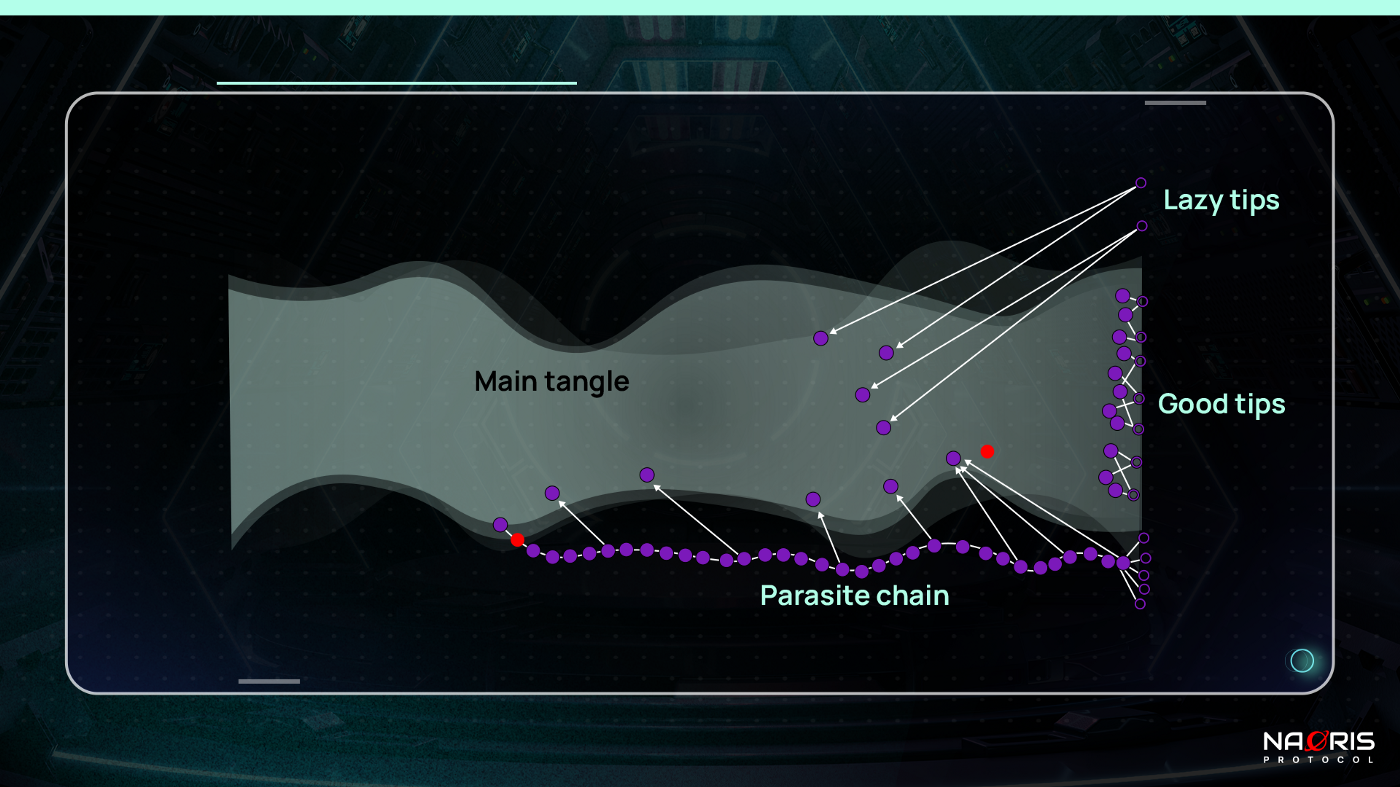
Figure 7 shows the tip selection algorithm for honest tips as well as the parasite tips. The red transactions indicate an attempted double spending.
One countermeasure to this attack is to use the only advantage the main tangle has over the parasite chain. The fact that the main tangle has more hashing power than the attacker. The main tangle is able to produce larger increases in cumulative weight for more transactions than the attacker. This is used by IOTA to create Markov Chain Monte Carlo (MCMC) algorithm to sample tips by independently approving all transactions from a given transaction to the tip. This is done by putting particles on certain sites called walkers. See more details of this attack here.
4. Splitting Attack: Here, the attacker tries to split the tangle into two branches and maintain the balance between them. This is a weird man-in-the-midle attack where the attacker places at least two conflicting transactions at the beginning of the split (to prevent an honest node from effectively joining the branches by referencing them both simultaneously. The attacker hopes that roughly half of the network would contribute to each branch to compensate for any fluctuations. (See red tips in Figure 7)
Conclusion
Let’s conclude with a summary of this episode:
1. DAGs solve problems such as micropayments, heterogenity between issuer and approver, block limits, etc. This makes for easily scalable consensus netoworks.
2. Despite the above, securing a DAG could be extremely difficult because it requires very precise selection of Tip Approval Strategy, Weights, and many other strategies to prevent known attack vectors.
3. Stability of a DAG is crucial because unlike the other consensus methods we saw, in some cases approval of transactions may be probabilistic especially taking into consideration the probability of orphaned chains, parasite chains, split subtangles, etc.
4. Weight capping strategies also are reasonable even against theoretically unbound adversaries like Quantum computers. E.g “large weight” attack would also be much more efficient on a quantum computer because nonces can be generated about 17billion times faster so O(√ N) instead of O(N). However, capping the weight would effectively prevent a quantum computer attack as well.
This Episode leaves some important thoughts:
- Is it possible to create a cleaner way to separate orphaned / invalid transactions from legitimate transactions? Issuer being mixed with approver does not mean legitimate transactions need to be mixed with illegitimate transactions.
- Is there a way to further improve transaction finality? In BFT terms, could we improve the liveness of DAGs in such a way that each transaction whether valid or invalid would have a result that would be more deterministic?
- Could we integrate another sort of consensus protocol as a Tip Approval Strategy to reduce the attack surface for DAGs?
Thank you for sticking with us till this point. Catch you in the next Episode!