![[EP -11] The Magic Behind Blockchain: ⇛ A Practical Example: Tendermint & Hotstuff ⇚](/_next/image?url=https%3A%2F%2Fuploads-ssl.webflow.com%2F660e449a26dad71301a18f76%2F66310c0dfe2cf36f980998c7_6630c2217450eb44a4fc14d9_63d2c94b125a1b0444fbf28a_1_wbKwYxo-8KC6TOdnVtoReQ_web.jpeg&w=3840&q=75)
Previously on Episode 10 of “The Magic Behind Blockchain”…
- We summarized the journey so far since Episode 1
- We delved into Directed Acyclic Graphs (DAGs) and its applications in Distributed Decision Technologies (Consensus-based technologies)
In this episode and the next, we will do something a little different. We will apply all that we have learnt so far to anlayze two real-world Blockchain examples (Tendermint and Hotstuff).
This Episode will focus on Tendermint. We will delve into how Tendermint works and analyze some of its strengths and weaknesses. The weaknesses, especially, will provide us with a great opportunity for future improvements.
WHAT IS TENDERMINT?
Founded in 2014 by Jae Kwon, Tendermint is the consensus protocol behind the Cosmos Network. Cosmos calls itself the internet of Blockchains basically because it allows data and asset exchange across multiple decentralized blockchains using its IBC (Inter-Blockchain Communication) protocol. Tendermint comes with a Cosmos SDK that allows developers to create a Tendermint blockchain quickly. The IBC protocol is for inter-chain communication.
Tendermint is created with Byzantine Fault Tolerance (BFT) as a blueprint. It is a high-performance State Machine Replication (SMR) system that essentially allows any software developer to create their own blockchain platform without having to build everything from scratch.
In Tendermint, each application can essentially be on its own blockchain unlike in Ethereum where multiple applications exist on one Ethereum blockchain.
As of 2022, Tendermint has been rebranded and is now known as Ignite. For our crypto investor readers, some notable coins hosted on the Tendermint-powered Cosmos network include: Kava (KAVA), Terra (LUNA), Band Protocol (BAND), Aragon (ANT), and Akash Network (AKASH).
Although the Cosmos Hub is a distributed ledger which has many asset types, there is a special native token called the atom. Atoms are the only way to stake, vote, validate, or delegate other validators.
METHOD OF ANALYSIS
In our analysis of Tendermint and Hotstuff, we will follow a simple 3-step approach:
- Decompose each protocol into the Blockchain framework we created in Episode 4 (Version 2 of the Mindmap).
- We will enumerate the key protocol assumptions that have been made and / or how it varies from the original BFT assumptions.
As a guiding principle, the further away you move from the core assumptions and operation of Classical (Ep 6) and Practical BFTs (Ep 7), the more mathematics and security verifications you will need to perform to ensure the correct and secure operation of your design.
3. Lastly, we will take a look at some advantages (pros) and potential problematic areas (cons) of each protocol. We end with the points to improve.
TENDERMINT COMPONENTS
First thing to note about Tendermint is that, unlike in Ethereum where you have a blockchain and different applications sitting on the Ethereum Blockchain as smart contracts, the Tendermint stack looks more like this below:
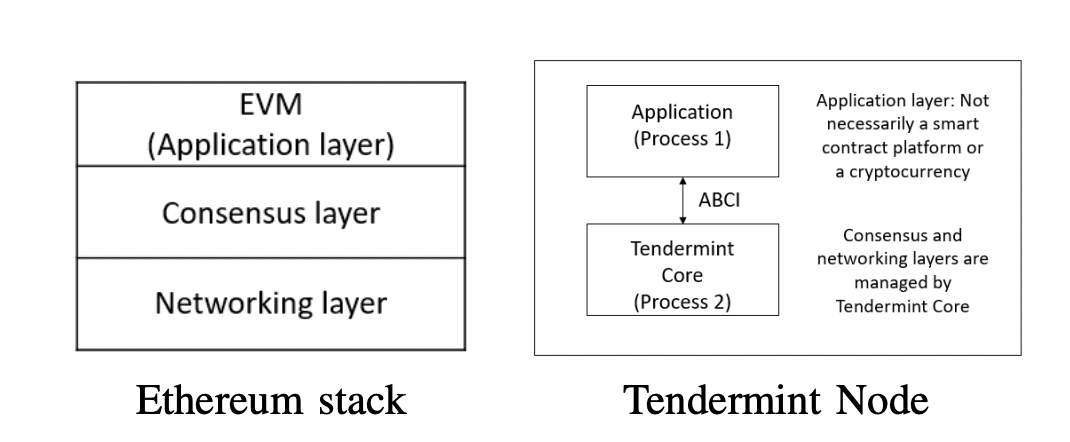
In the Ethereum stack, you have:
- the networking layer — in our framework, this is a combination of the Physical layer, peer-to-peer layer and content layer,
- the standard consensus layer
- And the application layer where the Ethereum Virtual Machine (EVM) is run. In our framework, the application layers is a combination of the primitives and advanced protocols
On the other hand, in the Tendermint stack, there are the follwing changes:
- A clear separation between an application, consensus and network layers.
- A node essentially runs two processes: The first process is the application which a developer compiled themselves into a process. The second process is the Tendermint Core which runs the BFT Proof-of-Stake consensus protocol and associated encrypted Peer-to-peer communications at the networking layer. Tendermint core makes sure that each transaction is recorded the same way on every node in the same order (State Machine Replication). These two processes communicate via gRPC (Google’s open source high performance Remote Procedure Call).
- For any Tendermint application process to communicate with Tendermint Core, the minimum requirement is to implement the Application Blockchain Interface (ABCI) which handle the gRPC messages.
- The ABCI enables the transactions to be processed in any programming language. So rather than using a pre-packaged built in state-machine in some scripting language, any developer can use Tendermint for BFT state machine replication of applications written in whatever programming language and development environment is right for them.
DIFFERENCES BETWEEN TENDERMINT AND PBFT
Tendermint uses a BFT Proof of Stake protocol. Unlike we saw in Delegated BFT, it doesn’t have a recovery mode and normal mode. It operates in a single mode. Since it is inspired by Practical BFT, all the steps of Practical BFT are used (identical) with very minimal changes. Some of the changes are:
- Tendermint refers to its primary as (coordinator/ proposer / leader) and the backup nodes as validators.
- Not all validators have the same weight of votes and leaders may be selected by any weighted round-robin scheme such as Proof of Stake.
- Tendermint calls the phases of the consensus algorithm: PROPOSE, PRE-VOTE AND PRE-COMMIT. This maps directly to PRE-PREPARE, PREPARE and COMMIT respectively. Refresh your memory with Episode 9 or detailed Practical BFT in Episode 7
- The 3 phases above occur in rounds where each round has a new Leader (primary) irrespective of whether the previous Leader was faulty or not.
- There is no View or View Changes. The closest thing to a View is a Round
Note: A round in Tendermint is NOT phase (eg: Propose, Pre-vote or Pre-commit). A round is a complete sequence of phases (Propose → Pre-vote → Pre-commit)
6. Unlike pBFT which terminates after COMMIT the phase when replies are sent, Tendermint terminates based on specific internal states called validround and validvalue. Therefore, there is no need for additional messages in transactions to terminate a the algorithm.
7. Tendermint also comes with a method of reporting faulty / dishonest nodes and providing evidence to facilitate other nodes to exclude them from the network. A sort of punishment for bad behaviour. Good cryptoeconomics here to keep nodes honest!
TENDERMINT FROM OUR PERSPECTIVE
Considering all we have learnt so far (especially the blockchain framework in Episode 4), we can now represent the core parts of Tendermint in our framework as shown below.
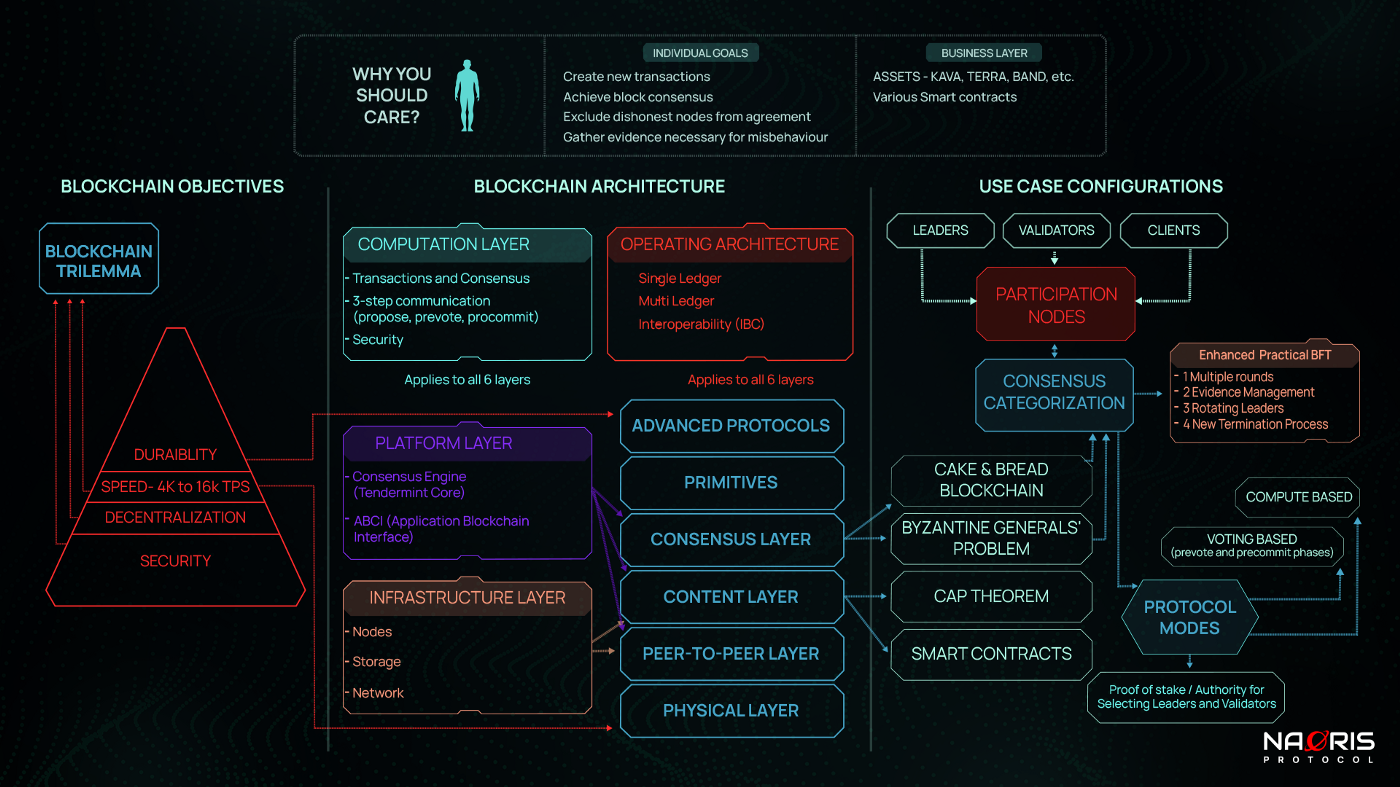
From the top of the diagram, Tendermint really aims to:
1. Facilitate the achievement of consensus of particular transactions in a block.
2. Weed out dishonest / faulty parties using its evidence Management system and Punishment. This is how Tendermint aims to incentivize good behaviour and disincentivize bad behaviour.
3. Specific users / developers to either create their own blockchain or make new transactions
The assets in the Cosmos universe are usually other blockchains, their associated coins and smart contracts. E.g. Terra, Kava, band, etc.
At the platform layer, Tendermint really consists of two parts:
The infrastructure still remains nodes, with their own storage in a peer to peer network. The standard blockchain layers (from physical to Advanced protocols) apply. This has been explained above in the Component section.
WHAT IS FUNDAMENTALLY MISSING / LACKING?
Tendermint is a great blockchain but it doesn’t do everything. In this section, we look objectively through our framework for potential weaknesses of the system.
Blockchain Trilemma
When we talked about the blockchain Trilemma in Episode 4, we mentioned Speed & Scalability, Security, and Decentralization. We added our own component of the Trilemma called Durability.
Sow how does this apply to Tendermint?
- Speed & Scalability: At 4000TPS to 16000TPS, this is a clearly highly performant system compared to other blockchains. Also the flexibility of developing your own blockchain that simply needs to communicate with Tendermint Core provides a lot of Scalability. How exactly is this speed achieved? Specific applications running on Tendermint have very high responsiveness because Tendermint nodes only exchange and validate transactions for one application. Performance can also be improved by using IBC via sharding (or horizontal interoperability). This is very similar to multi-threading in processors, sharding allows multiple blockchains to run the same application in parallel; therefore achieving higher throughput
- Security: High speeds and high scalability means that you are constantly adding new applications, nodes, potential functionalities. All transactions are being performed at a high rate as well. In summary, you are adding more and more attack vectors without an in-built blockchain way to test all attack vectors and control the large attack surface that is developing. Note that Tendermint applications could be as simple as key-value stores to an application like Ethermint which is a basically a project which simulates the Ethereum EVM on Tendermint. Later we will see some critical vulnerabilities that have occured on Tendermint historically.
- Decentralization: Access to the Cosmos network and use of Tendermint Core is pretty much very decentralized. However, the locus of power on who gets to the decide the next block is much less decentralized. With BFT Proof of stake not everyone has enough financial resources to stake. And there is no clear built in consensus process to democratize who gets to participate in governance regardless of new blockchains built on top of Cosmos.
- Durability: Separating the application layer from the consensus layer comes with a lot of advantages. This is the main Tendermint feature that provides such flexibility to developers to develop in their own programming language (Go, Python,Pharo, C++, Java, Ruby,…)and their own blockchain. However, in terms of availability, both the application layer and consensus layer must interact without any interruptions, stopping, timing issues, race conditions, etc. And this must happen for all individual application-based blockchain processes built on Tendermint. For this to be standardized there should be clear in-built processes that check for continuity of operations between applications and Tendermint core. This is another point for improvement. An example is that assuming you find a vulnerability on the Tendermint core side and fix this problem. Say a variable overflow like the one found here. Durability means that the system automatically replicates changes to all applications as well. So the problem really is maintaining the flexibility advantages of separating the application and consensus layer while maintaining continuity and collaborative functioning between the layers.
In summary, Tendermint prioritized very high Speed & Scalability as well as Decentralization. However, the true cost / sacrifice made here now and in the future will be Security and Durability. How to provide guarantees for this as the Cosmos network scales with more functionalities.
CAP Theorem (Safety and Liveness Comparisons)
Basic explanation of CAP Theorem: It is impossible to achieve Consistency and Availability in an unreliable system (system with failures / Partitions). See Episode 4 for more details.
To easily determine what is prioritized and / or sacrificed here, we need to ask ourselves 3 questions:
Does Tendermint operate in a fully synchronous network?
What actions achieve which property?
How do we compensate for the sacrificed property?
Does Tendermint operate in a synchronous network? Fully synchronous system means every process has a clock time, every message is delivered within a known amount of time and every process takes place a fixed or known rate. When you look at the Tendermint BFT Proof of Stake Protocol, we already know the assumption is Partial synchrony. Why did we ask this question?
Well, you can only avoid the trade-off between Consistency and Availability is to operate in a fully synchronous network.
What actions achieve which property? First of all, Safety means nothing bad ever happens. Therefore, Consistency is a classic safety property. If every client receives a correct response (which is the essence of consistency) then nothing bad will happen.
On the other hand, Liveness is a guarantee that the system will not stall / hang forever. Eventually something good will happen. Availability is a classic liveness property. Eventually every request / transaction should receive a response.
We already know that Proof-of-Work type consensus algorithms prioritize Availability and Liveness over Consistency and Safety. PoW just takes more time to align on a block so availability is crucial. Therefore if some parts fail / exceptions occur, you just allow forks which are temporal literally inconsistencies. At least save the data you are have even if it is inconsistent.
BFT-type consensus algorithms prioritize Consistency and Safety over Availability and Liveness. This just means consensus happens really fast so you better make sure those fast decisions are correct and consistent. Speed here is generally not a problem so most move to guarantee Consistency and Safety. They are usually non-forking and would rather halt the entire chain if there is a partition of faulty nodes in the network. This hopefully happen rarely.
Tendermint intentionally allows a different leader to be voted for each to make sure that no matter what happens in the network, someone will ensure a good block is created. Voting to skip proposer, determining malicious leaders and validators is all a sign that they are going the extra mile to guarantee Consistency and Safety. Availability and Liveness is completely sacrificed here.
How do we compensate for the sacrificed property? The impact of sacrificing Availability and Liveness in Tendermint can be felt on two levels:
- Application level: Blockchain applications built on top of Tendermint may fail in several ways. Tendermint core does not exactly provide your clients liveness alternatives for this. This is hard to do since every application is so flexible and different.
- Tendermint core level: If more than 2/3rds of the validators somehow experience a fault due to network or new software update issue, DDOS attack, the entire system halts. Only a manual hard fork and intervention will bring things back on track.
It is obvious that the risk of this sacrifices was accepted because:
- Tendermint operates in an Enterprise environment unlike Ethereum
- Most of the validators are known, therefore, semi-honest
- Blockchains built with 1 and 2 in mind usually have fairly reliable networks.
However, accepting a risk does not always mean the impact is acceptable.
As a blockchain supposed to be built for the “cosmos” specific use cases that have high availability requirements cannot be safely developed on Tendermint since sacrificing availability in any case is not an option. Also this indirectly imposes an economic cap on how much can be invested on a Tendermint project.
In the future, an improvement here would be to aim for Eventual Availability / Liveness or even Best-Effort Liveness. Tendermint core could run an upgrade that allows the developer to choose which property to sacrifice depending on the use case at hand. The is in-line with their flexibility. This means certain segments of the Cosmos will prioritize Consistency and Safety while other Prioritize availability. Also there could be a fail-over consensus protocol that is potentially forking ONLY for the rare cases where 2/3rds of the network has collapsed.
NO PRIVACY OR NETWORK TRUST GUARANTEES
Never forget that Tendermint is a permissioned Blockchain. It is not free-entry, therefore, the identity of each node is known to the whole network. This might not be ideal for certain use cases.
Additionally, how Tendermint works is that: Each new blockchain (or application) deployed has its own network. Initially, this network is usually managed by the programmers themselves! This requires a lot of trust from users! As time goes on, trusted-third parties may arise who would propose a globally ubiquitous application-less nodes to these programmers. If the programmers accept, they send the application to these trusted third parties and the application becomes “independent”.
Fair warning: If we look at a purely adversarial network, I would define a Trusted-Third party as any entity who could violate your security and privacy and get away with it. Trust but monitor and verify!
INCOMPLETE BLOCKCHAIN INTEROPERABILITY
Tendermint allows a certain level of interoperability between blockchains (application processes that communication with Tendermint core). Mostly, this at the time of writing is limited to value transfers. Example transferring coins from one Tendermint cryptocurrency chain A to another Tendermint cryptocurrency chain B. Even these value transfers are limited to non-forking consensus engines. Meaning Proof of Work type Blockchains like Bitcoin or pre-Casper Ethereum cannot interoperate value with Tendermint.
What more is missing / incomplete from this interoperability is that there is no way for one Tendermint chain A to call a function in another Tendermint chain B. This level of interoperability is almost a requirement if we look at the Cosmos’ vision — “s to create application-based blockchains which can easily communicate with each other”
In this regard, if you compare these Tendermint application processes to Ethereum Smart Contracts, there is already a severe Interoperability limitation.
INCOMPATIBILITY WITH NON-DETERMINISTIC APPLICATIONS
A deterministic application / program is one that will return the same result if it is given the same input. A non-deterministic application may return different result even if the same input is supplied.
Tendermint does not natively support non-deterministic applications. This means not all use cases are possible. This means, if a programmer connects a non-deterministic application to Tendermint Core, it is very likely that consensus will not be achieved and the application will become vulnerable. Tendermint blockchain programmers have to take precautions of respecting deterministic coding conventions. They could therefore use SAST tools to analyze their code before connecting it to Tendermint core. All these problems are not existent on other platform like HyperLedger Fabric. Ethereum’s solidity is also completely deterministic by design so no extra precaution needs to be taken by developers.
POSSIBLE COLLUSION OF IBC RELAYERS
In order to achieve Inter-Blockchain Communication (IBC), it should be noted that the IBC protocol does not directly route data packets from one Tendermint chain to the other.
The reality is that there are proxies called IBC Relayers. The IBC protocol inserts data packets into the incoming and outgoing queues of IBC Relayers. Who are these IBC Relayers? How does one become an IBC Relayer? Is it a democratic process? Who keeps IBC Relayers honest?
First of all, it requires some very heavy machinery to be an IBC Relayer and there is no obvious in-built consensus incentive to these IBC Relayers who essentially act as a bridge between chains.
IBC Relayers should not be able to collude in order to adversely affect any chain.
However, there are no clear in-built guarantees for this. An example attack is as follows: Imagine a developer deploys Application E which is an exchange platform or a stock market between many chains, IBC Relayers can theoretically collude to relay packets from a specific chain first in order to control supply and demand.
We suggest the following ways to compensate for the above risk:
- There should be a clear economic incentive to encourage nodes to relay the packets themselves. Some sort of rewards.
- In order to keep liveness and availability, specific long-term Relayers can be selected using the same BFT Proof of Stake consensu algorithm. The evidence and punishment scheme like slashing must also apply to them.
- IBC Relayers could even intentionally slow down / attack other relayers in other to monopolize possible rewards. If any Relayer is found monopolizing, they must stake more in order to become a Relayer. The fee could be democratically calculated based on the state of the network (number of active relayers, number of unpaid relaying, relaying speed, network load, etc.)
HOW TENDERMINT ACTUALLY WORKS
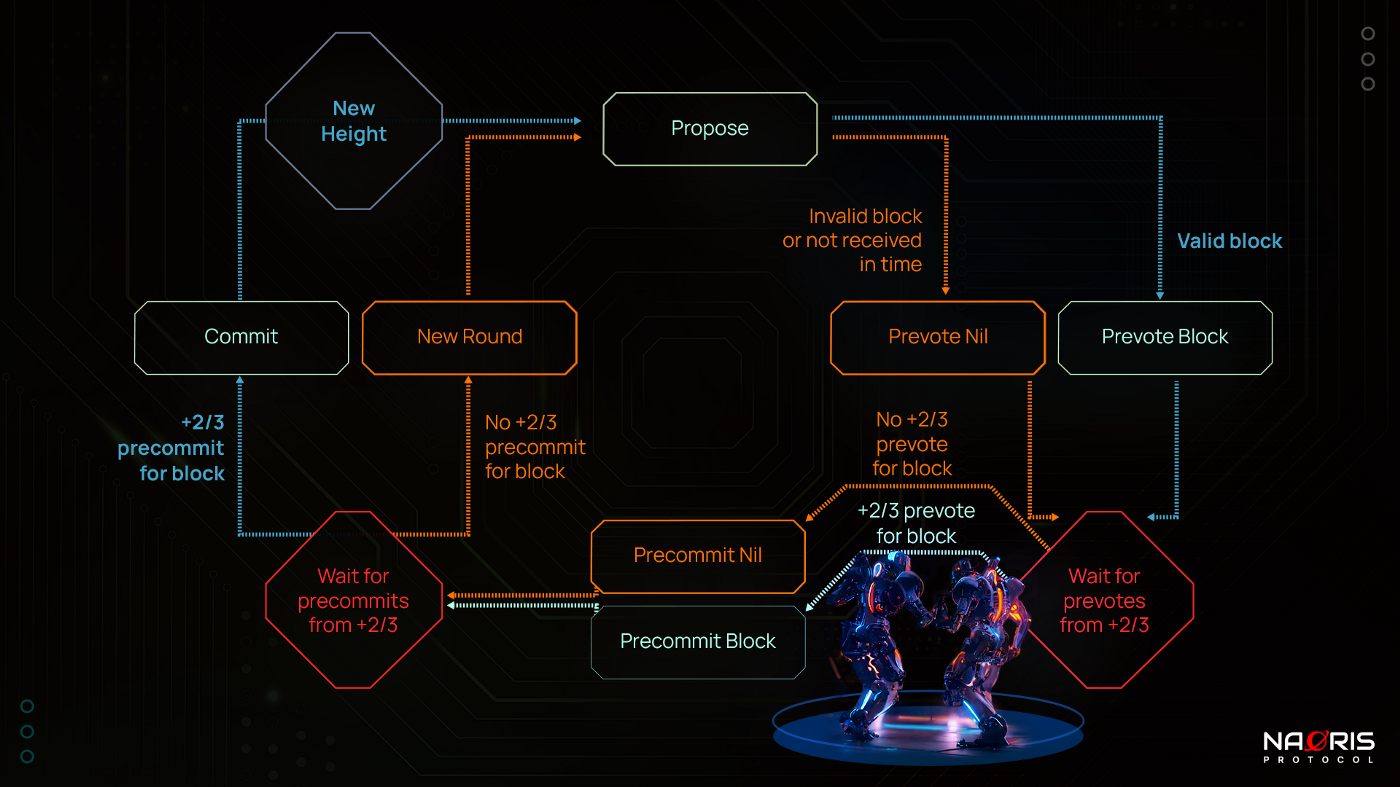
- When a round starts, a leader is selected by an algorithm (dependent on the specific application). The algorithm is usually a weighted round-robin function of the form leader(height, round).
Careful attention should be paid to the leader selection algorithm. There should be sufficient entropy (randomness) for this selection, similarly, the source of the entropy should not be centralized.
- The leader chooses a group of transactions from the Mempool and creates a new block and broadcasts it to the validators. This is the PROPOSE phase. This message contains the block itself, the leader’s signature, the current height and round. In the next phases, only the Block ID is sent which is usually a hash of the block.
- Validators check the block and vote for the block (Pre-vote phase) or disapprove the block if there are any conflicts by Pre-voting a NIL value. Note that this vote is done by broadcasting the particular pre-vote message to neighbouring nodes.
- After any honest node receives a PROPOSE message and 2f + 1 signed PRE-VOTE messages in the same round r, this is already a good point to note that a decision is about to take place.
- If an honest node receives 2f+1 PRE-VOTES in the same round r, it PRE-COMMITS the block else it PRE-COMMITS a NIL value. If after a particular time, a pre-commit is not reached, the node times out the process and moves to the next round (Pre-commit timeout). This is crucial to liveness of the consensus algorithm.
- Finally, when a node has received 2f + 1 signed PRE-COMMITS, it enters a new round and commits the block, going to a new blockchain height. A new timer starts.
Fun Fact: In Tendermint, the end of stage 4 is called a Polka. As shown in the picture above because it’s like the validators (robots) are doing a polka dance. When more than 2f + 1 validators pre-vote for the same block, we call that a polka. Every pre-commit must be justified by a polka in the same round.
ALGORITHM TERMINATION AND STATES
Every node maintains state of certain key variables:
- step: current state of internal machine, thus, current stage of algorithm in the current round
- lockedValue: most recent block with respect to the current round for which a pre-commit has been achieved
- lockedRound: last round in which process sent a valid pre-commit which is not nil
- validValue: most recent block for which a Polka is achieved
- validRound: most recent round for which a Polka has been achieved
- round, height: current round and block height
Whenever an honest node has received a Polka (PROPOSE message and 2f+1 PRE-VOTE messages), it sets its validValue to the current block for which the Polka was received and validRound to the current round for which the Polka was received. This is then translated into lockedValue and lockedRound respectively. Once this is done, the node can send its PRE-COMMIT message.
If a node locks a validValue = v in validRound = r, all honest / correct / non-faulty nodes, by deduction, will have the same states for validRound and validValue before the end of the round. This is simply because all Pre-votes would have been circulated (gossiped) to other nodes as well leading to the nodes eventually changing their state and PRE-COMMITTING.
This means: with validValue, validRound and gossip, eventually within the rounds, a commit will be reached and the process will be terminated without the need for any other special transactional information. This type of termination removes the need separating normal mode and recovery mode. The constant round changes also are a perfect substitute for view changes.
EVIDENCE MANAGEMENT
There is one little caveat with substituting view changes for alternating rounds. Using a different proposer / leader for every round will definitely ensure that a dishonest leader will not control too many rounds deterministically. However, it still doesn’t remove the risk of an adversary that controls several nodes who could also become leader nodes. At least with dBFT 2.0 we could detect a dishonest leader and trigger a view change but here we don’t have that. There is no native transactional concept of Node Recovery in Tendermint as exists in dBFT 2.0.
Therefore, we need two things:
- A way to report and punish faulty nodes
- a proactive way to prevent nodes from going out of sync or accept the risk of nodes out of sync.
The internal states are quite helpful here but Tendermint goes one step further to also help you need to detect, report and exclude dishonest / faulty nodes. This is the point of Evidence management.
If any honest node detects that another node is behaving suspiciously, it sends evidence of the faulty behaviour (e.g. conflicting transaction in a particular block, mismatching hashes, etc.). This goes through a very similar process as a regular transaction. And once the nodes reach an agreement with majority of nodes reporting the same faulty node and evidence, the node is given a penalty as punishment for the faulty behaviour.
KEY ASSUMPTIONS
Now let’s go into some of the main assumptions we can draw from the Tendermint consensus protocol.
- Adversaries are semi-honest. This means that Tendermint assumes that blockchain users will follow the protocol most of the time since it is a permissioned ledger anyway. Thus, they are able to keep consistent data most of the time.
- Operates in Partial-synchrony
- Safety is only guaranteed when there are at least n = 3f + 1 nodes, where f is the maximum number of simultaneously faulty nodes.
- Liveness is provided with Pre-Commit Timeouts and Round Changes.
- View-changes are not needed because each round has a new Leader (or Proposer) and there is an Evidence Management protocol in place.
- Nodes going out of sync are an acceptable risk. This is an implied assumption with the absence of a native transactional node recovery.
- All transactions are well-ordered in the same way by the majority (2f + 1) of nodes.
- System revolves around 3 principles:
- Agreement — No two processes decide on different values. Works like Safety
- Termination — All correct processes eventually decide on a value (like liveness)
- Validity — A decided value is considered valid if it satisfies a particular function or condition. This is application specific in tendermint. In other blockchains, it may be appropriate hash of previous block, etc.
PROS
- It is a very simple algorithm that is really easy for developers to code. In fact, there is a straightfoward pseudo-code on Page 6 of the Tendermint Paper.
- Compared to other capacity consuming consensus protocols (like Proof of Work) discussed in Episode 5, this is Hybrid protocol (part Gossip-based and part Proof of Stake / Authority). Therefore, it consumes comparatively less resources and achieves higher speeds.
CONS
- There is no clear in-built way to recover nodes (as in dBFT 2.0) that have lost consensus. Is the assumption that re-introducing the node and syncing data solves the problems? Or do you need to export a new genesis state and rejoin network? Are fast sync and state sync features triggered in all cases? Are there any edge cases? These are all questions the require consistent answers once we do away with the checkpoints in pBFT and node recovery / regeneration in dBFT 2.0
- Very careful attention needs to be paid if consensus is performed on any other types of transactions that directly influence regular transactions. For eg. If one wants to achieve consensus on evidence transactions that prove that a node is faulty, this consensus process should not interfere with normal Tendermint transactions. It should be non-blocking. Remember the Durability rule in Episode 4. Look at the following Vulnerabilities that were actually discovered on Tendermint.
- Penalization and Evidence Issues: Who, when and how to punish misbehaviour is a huge problem both technically and democratically. The are 4 main scenarios:
- Detectable malicious behaviour — This is any activity of a node that is clearly against the consensus protocol. This is easy to detect and admissible evidence collection is easy. Therefore, it is easy to provide a consistent punishment such as slashing a percentage of the malicious validator’s staked atoms (Cosmos network currency).
- Undetectable malicious behaviour — Some malicious behaviour are not obvious to the consensus algorithm and may not produce any admissible evidence on the blockchain. In such cases, punishing malicious valdiators become very tricky. Tendermint suggests a anon-defined off-chain consensus process to forcefully isolate the malicious node from the network. This has many questions, who decides which node is guilty if evidence was not overwhelming in the first place? What is the false positive rate? And there is a clear impact to democracy. The most important question here is:
If we were going to use an out-of-band(off chain consensu / oracle) process to determine and punish malicious nodes anyway, why was this not part of the default consensus algorithm. There are so many ways to violate the Durability rule once you start running uncontrolled off-chain oracles that decide things on-chain.
- Detectable honest failure — Imagine there is a validator or group of validators that just have bad internet connectivity. Being offline too many times makes them undependable. There is no consistency to when they vote or when they don’t. This could have serious consequences of liveness and in rare cases may impact safety if there are enough of such nodes. Therefore, there is a need to motivate validators to be more dependable. If, at any point in the past ValidatorTimeoutWindow blocks, a validator’s commit vote is not included in the blockchain more than ValidatorTimeoutMaxAbsent times, that validator will become inactive, and lose ValidatorTimeoutPenalty (DEFAULT 1%) of its stake. In certain specific Cosmos based applications like Cheqd, delegators may also get slashed if they are delegated to a Validator which experiences downtime. Such a delegator may redelegate their stake to another validator within a 3-hour window to avoid being slashed. Note that this only applies to this type of failure (downtime slashing / soft slashing
- Massive Detectable honest / dishonest failure — What if a large part (more the one-third) of the network goes offline due to some network reason or catastrophe. Or if more than one-third of validators decide to go rogue. In this case, Tendermint provides an option for the hub to recover with a hard-fork reorg-proposal.
Also note that a validator’s punishment on the network range from instant, irrevocable expulsion at a cost (as in the instance of duplicate voting) to time-outs from extra Staking payments and a change in validator’s rating.
Evidence is essentially another chain on its own that influences the main chain. This should be a non-blocking operation. So if you decide you have enough evidence, all nodes must already receive the block in question or node in question before they act. Block must be committed.
Punishment must go through on-chain consensus as well even with undetectable behaviour. Without this any off-chain punishment process must have at least the same security, democracy and trust as the main chain and leave a good historical trail of actions.
PREVIOUSLY DISCOVERED VULNERABILITIES
In 2021, two crucial DDOS vulnerabilities were discovered on Tendermint v0.34.0 after they introduced a new process of handling evidence of faulty / dishonest / misbehaving nodes.
VULNERABILITY 1
January 8, 2021 — This vulnerability leveraged an edge-case in the evidence handling process. If a node is exhibiting malicious behaviour, e.g. publishing a conflicting (say double-spending) transaction in a block, other nodes can collect evidence of this and announce the evidence to other nodes. But there is a crucial caveat here! The evidence of malicious malicious activity must have occurred on some block. What if the block has still not reached all nodes? What if it is not yet committed? What if the block is still in flight? Any node receiving this evidence will look for the block as input to the evidence. If it is not found, the node will go into a panic. This will then lead to a Denial of Service. This is the essence of the Durability rule we discussed in Episode 4.
VULNERABILITY 2
January 13, 2021 — This vulnerability also leveraged a similar caveat as in vulnerability 1. When a node tries to create evidence on misbehaviour, it also calculates a timestamp using an algorithm that relies on the timestamp for the lastCommit of the block in question. This means if a block is still “in-flight”, different nodes may have a different lastCommit (which depends on when they create their evidence). The edge case becomes that two validators (nodes) will end up with different timestamp values for the same evidence.
Of course one of the evidence transactions will be accepted and added to the block but the other will be dropped because it is a duplicate (“invalid evidence”). Now this looks like the node sending the invalid evidence is just making a false accusation (although they sent the right evidence but with the wrong time). Future evidence created by this node building on this evidence will also become untrusted and be labelled as invalid. Eventually, the Tendermint network may choose to block this node from participating in transaction. This is effectively a Denial of Service.
CONCLUSION
Spending some time in rigorous testing of protocol especially new additions, edge cases and assumptions made is a worthwhile investment. This is especially true if Security and Durability is the main sacrifice of your solution. In fact, we can summarize the steps we should follow when we decide to create a new consensus algorithm or blockchain type:
- Enumerate the various use cases you need for your new blockchain. This is essentially to ensure scalability. If this is not done correctly, you will have to bolt on new features and workarounds, thereby, increasing the chances of introducing vulnerabilities.
- Put your new design in the framework to get a holistic view of the key moving parts that affect the various layers of the blockchain, blockchain Trilemma + Durability, consensus categories, CAP theorem, etc.
- If there are no serious conflicts from above, make a quick gap analysis of the differences between your design and those mathematically proven in literature. This gap analysis essentially will show where you have made assumptions.
- Put in compensating controls / features if something has been sacrificed
- Test edge cases via cryptographic and security analysis.
- Do extensive implementation reviews such as running SAST, DAST, human penetration testing, etc.
- Consider Durability whenever you perform any actions off-chain.
In Tendermint, we saw the various issues (DDOS vulnerabilities) that arise from introduce Evidence Management and Punishment. This is quite similar to the vulnerability that occurred in dBFT v1.0 when they decided to remove the commit stage of the protocol without going through these steps
TENDERMINT BEST PRACTICES
I would also like to end this by providing some Tendermint specific best practices to developers, users and potentially the Tendermint team:
- Access Control on Tendermint Home Folder: A Tendermint node runs from a home folder on the computer. Therefore access to this folder is critical. If someone deletes this folder, the node will effectively crash. Similarly if an attacker gets physical access to the hard disk or remote access via some port to the Home Folder on a node, they could essentially control the node. Replicating the same attack across at least 2/3rd of the nodes in the specific application-blockchain network means that this attacker could essentially thwart the entire consensus protocol for that specific application-blockchain running on cosmos. Tendermint could in the future provide a Blockchain-agnostic way to encrypt and control access to this home folder.
- Preventing Common Application-Specific DDOS attacks: In Tendermint (< 0.19.5), it was possible to halt a node by sending thousands of requests via HTTP. This collapse occurred because Mempool was not handling the load correctly. Although Tendermint 22.6 overcomes this problem, the same attack yields an error message saying Mempool is full. An attacker can still have a variant of this attack by sending thousands of HTTP messages to the node, keeping the Mempool full and preventing the node from validating other legitimate transactions. This attack can originate from any source, even a browser script, therefore the attacker does not need to have control of a Tendermint node. It is recommended for users to prevent their node from responding to external HTTP requests by changing the RPC listen to address, from the default value to “localhost: 26657” in the configuration file.
- Even better solutions to the above is to use of reverse proxies, stated modifications concerning the configuration file, firewalls, TCP connection guards to mitigate spam attacks via P2P layer.
- Choose Chains to trade with wisely.
In the next Episode, we go into detail about Hotstuff using the same type of analysis here and make some efficiency comparisons between Tendermint and Hotstuff.
Catch you later!