![[EP -9] The Magic Behind Blockchain: ⇛ Delegated BFT 2.0⇚](/_next/image?url=https%3A%2F%2Fuploads-ssl.webflow.com%2F660e449a26dad71301a18f76%2F66310c111158001e4267c563_6630c224e72ee36334ee92c3_63d2c94b125a1b6532fbf268_naoris-protocol-ep9.png&w=3840&q=75)
Previously on Episode 8 of “The Magic Behind Blockchain”…
- We looked at Delegated BFTs
- We understood what makes dBFTs different from the Classical and Practical BFTs
- We looked into the key improvements made in Delegated BFT v1.0 (in terms of time and space complexity) and ended with some pros and cons of these changes.
- We saw the cost of omitting / sacrificing the pBFT Commit phase in dBFT v1.0 for efficiency. The cost of this sacrifice was security, safety and liveness issues. See the Security and Attack vectors section of Episode 8.
In today’s episode, we will take a deep dive into Delegated BFT v2.0 and attempt to resolve the security, safety and liveness issues created mainly by the omission of the Commit Phase is Delegated BFT v1.0.
UNDERSTANDING THE KEY PROBLEMS OF DELEGATED BFT v1.0
If we remember the phases of Practical BFT (where dBFT v1.0), we know that we had Pre-prepare, Prepare, Commit and Reply phases
Now let’s abstract the true meaning and intent of these phases to understand where we went wrong in dBFT v1.0.
- Pre-prepare Phase: The intent of this phase is to make sure a “democratically” elected primary responds in a timely manner to client requests and that all backups can validate the sequence number, view number, block height (in cases of dBFT) and the fact that a request actually came from a primary. If every backup node can say: “I can personally confirm this is a valid request”, then they store it in their logs and spread the good news (or broadcast it) in the next phase. This first layer of safety prevents invalid / fraudulent transactions and wrongly ordered transactions from being circulated in the network. In other words, it prevents the spread of inaccurate information.
Note that the primary node has a lot of power in this phase, without having view changes and each backup individually validating that the primary is acting honestly, fraudulent transactions could easily be propagated into the next phase. So we trust the primary node but not blindly!
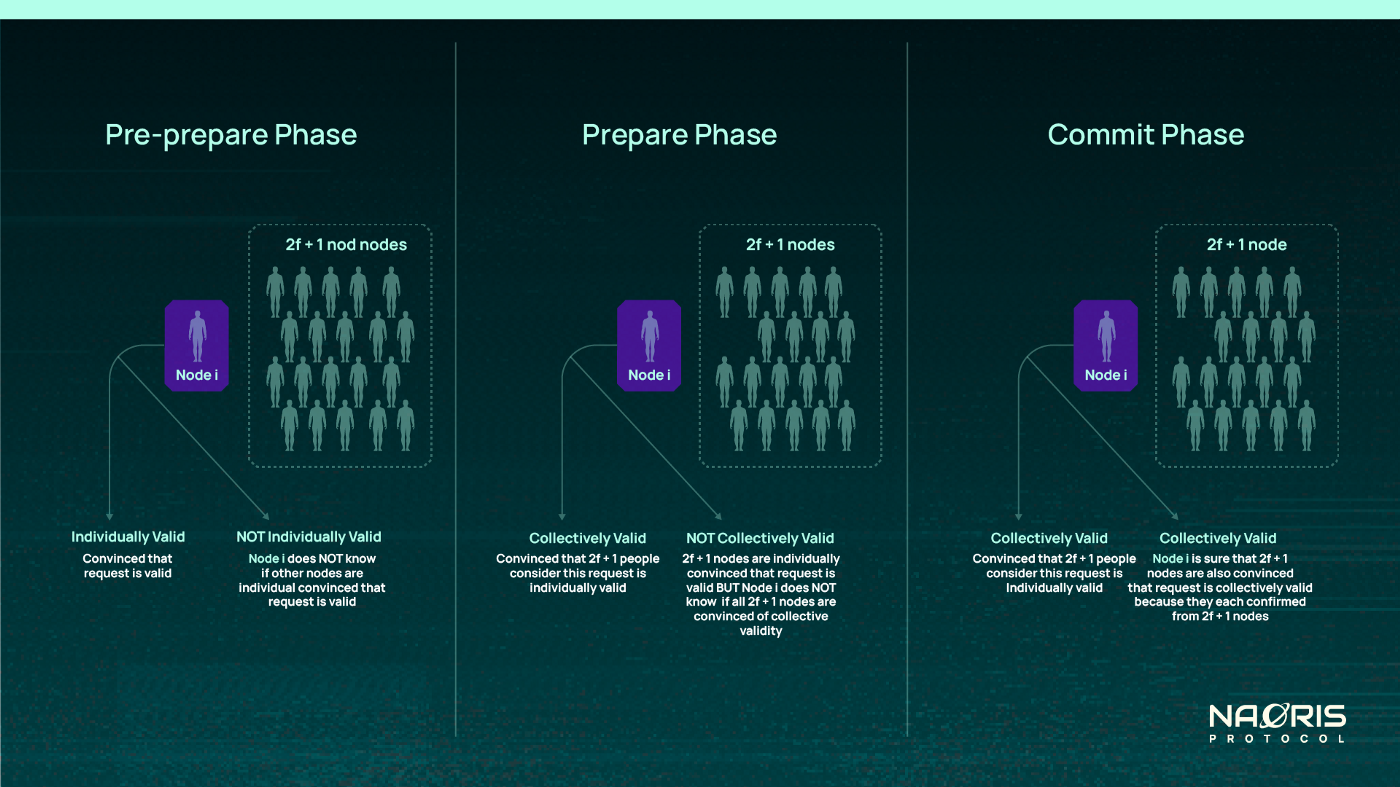
At the end of this phase, each node is individually convinced about the validity of a transaction to a certain degree but NOT so fully that we can execute it.
2. Prepare Phase: The intent of this phase is to spread good information and increase trust in the request received from Pre-prepare phase. After Pre-prepare phase, each node individually knows whether or not it individually considers a request as valid. However, it doesn’t know whether the same request is considered collectively by other nodes as valid.
Note that, the fact that a transaction is considered as individually valid by one node does NOT necessarily mean that it is also considered as collectively valid. This is the reason why each node broadcasts what it considers as a valid request to other nodes.
If a node receives 2f + 1 similar confirmations of the same request, sequence, number and view number, that node now knows that at least 2f + 1 other nodes are also in agreement. So this increases the trust of the request from individually valid to collectively valid. In essence each node is in a position to say: “I can confirm that a good majority of nodes (2f + 1 nodes) also consider this transaction valid”. The other nodes are convinced because they themselves checked individually. Maybe they are not fully convinced.
3. Commit Phase: This phase is the most counter-intuitive phase so let’s use an analogy to clarify it. Imagine that we wanted to create a way to ensure that only accurate news spreads in a network. In other words, we want to prevent fake news from spreading like wildfire. It will go like this:
- Someone with a particular news item announces it to a leader (primary) and primary is trusted to verify the news and its source.
- Primary broadcasts it to everyone. Everyone (backups) individually verifies it to be sure before storing the news. This is the Pre-prepare phase. So your mind is now in an “individually verified / valid” state.
- You never truly know if you verified it well so you broadcast to other nodes and wait to see if a majority of people (2f + 1) also individually verified that news. This is the prepare phase. If you receive 2f + 1 confirmation, your mind can graduate to the “collectively verified / valid” state. This is the Prepare phase.
- Now you know you have verified this news yourself, you also know that 2f + 1 people have individually verified this news because they told you in the Prepare phase. What you don’t know here is if these 2f + 1 people are also in the same mental state as you (the collectively verified state). It may be that after sending you their individual validation, they never received enough messages as you did, so somehow they never got to the collectively valid mental state. They may still be in the “individually verified” mental state. This is why you need another round to ensure that they can also confirm that 2f+1 others have verified their state.
This is the essence of the commit phase: To ensure that 2f + 1 other people have confirmed that they have also confirmed individually from 2f+1 people that a particular request is valid. In summary, a node after a commit phase should be able to say: “Look, I have confirmed that the majority of people (2f + 1) have reached the collectively verified /valid mental state. Only few people remain in the individually verified state”.
4. Reply Phase: Only after the majority has reached a collectively verified mental state can you conclude that majority will agree and therefore execute the request and send a response back to the client.
ABSENCE OF THE COMMIT PHASE
In dBFT v1.0, we saw that the commit phase was omitted / removed. The flawed assumption made here was that: “there is a high probability that if one node reached the “collectively verified /valid mental state”, the majority of others will automatically follow suit”.
However, it allows for exceptions. Because the mere fact that you are fully convinced does not mean that everyone else is as convinced as you are. They may be convinced but not to the same level as you are. If anything unexpected happens between the time when you are fully convinced and the time when everyone else is fully convinced (eg. network issues, rogue primary, rogue backup, etc), a loophole is opened that will eventually allow disagreements. This is the root cause of the security, safety and liveness problems in dBFT v1.0.
In essence, it was possible to have more than one valid block at the BlockSent state at the same height (Fault fork and Hash fork). This meant that nodes didn’t know which next block to choose even after the consensus algorithm has been fully executed. In other words, to consider a block final (block finality), you need an extra manual step. Otherwise the whole Blockchain halts waiting for clarification. This affects liveness.
The requirement to avoid any exceptions is therefore that, each Node i must move from a mental state of being individually convinced about a request to being collectively convince AND also knowing that 2f +1 nodes are collectively convinced. This is shown below:
DELEGATED BFT VERSION 2
From the above, we now know that we need the Commit Phase to solve some of the main attacks discussed in the previous episode. However, even if we had the commit phase, we wouldn’t be able to completely solve our fault forking issue.
Even with the commit phase, after a node has reached a committed state, it could suddenly lose internet connectivity and return only when the other nodes have decided on a new block. This will lead to halting of all nodes that are misaligned with the majority in terms of the latest block.
Due to the above, we also need to explicitly ensure that if a node has reached a commit phase on a particular block, that node will not sign any other proposed blocks before the current one is finalized. This is called View blocking / locked View Changing.
If we implement view blocking, there is always a chance that when a node commits to a block and suddenly loses internet connectivity, we need a strategy to re-align the node once it regains connectivity. This is called Recovery / Regeneration.
DELEGATED BFT version 2.0 ALGORITHM
In dBFT v2.0, a clear distinction is made between the type of nodes and the kind of operations they can perform:
- Normal Node: This is node that can transfer and create individual transaction but can NOT propose new blocks or vote a proposed block
- Consensus Node: This node can either propose a new block and / or vote for a block that has been proposed. They are part of the election process.
- Candidate: A node that is nominated to participate in being elected as validator.
- Validator: A node elected from candidates to become a consensus node (take part in consensus).
- Speaker: A validator in charge of creating and broadcasting a proposal block to the network.
- Delegate: A validator responsible for voting the a block proposed by the Speaker.
Before we move to the actual steps of the algorithm, let’s take a look at all the kind of messages that can be transmitted in a dBFT 2.0 network:
- Prepare Request: This message is sent in the first phase (Pre-prepare or Prepare Request phase). It is sent by a primary / speaker to start the consensus process.
- Prepare Response: This message is sent in the second phase (Prepare or Prepare Response phase). This informs backup nodes (validators) that all necessary transactions have been collected for block creation.
- Commit: This message is sent in the third phase. Unlike dBFT v1.0, dBFT v2.0 contains the commit phase. The commit message informs other validators that enough Prepare Response messages have been collected.
- Change View Request: This message is for changing view and hence the primary (speaker).
- Recovery Request: This message is sent by a node which recently encountered a fault to request for consensus data synchronization
- Recovery Message: This is the actual data payload that is sent in response to a recovery request. It helps restore a faulty node back to recovery (see regeneration process above).
DELEGATED BFT VERSION 2 STEP BY STEP
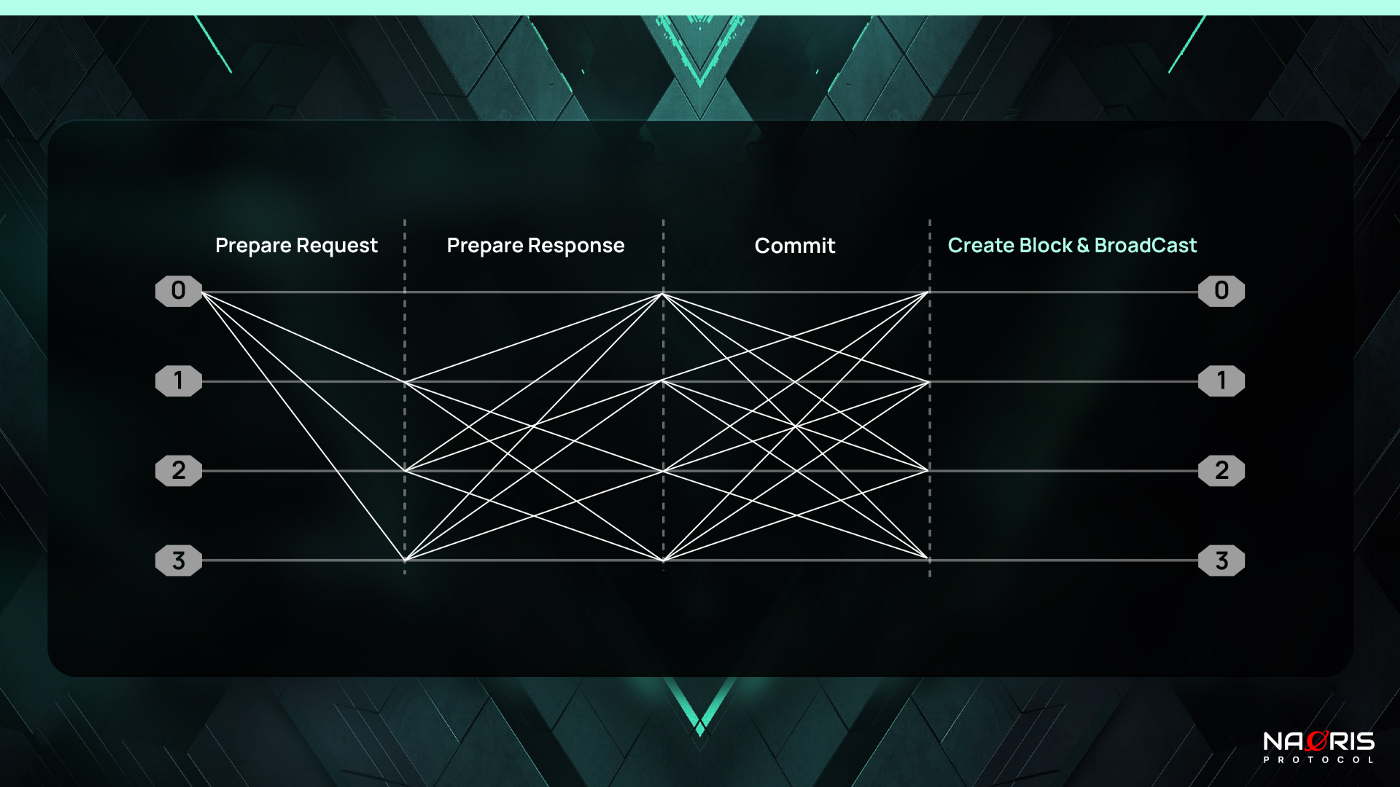
A round of consensus consists of 3 key phases + broadcast / reply. Note that the Commit phase which was abandoned in dBFT v1.0 is re-introduced.
- Speaker starts consensus by broadcasting a Prepare Request message (Pre-prepare phase)
- Delegates broadcast Prepare Response after receiving the Prepare Request message (Prepare phase)
- Validators broadcast Commit after receiving enough Prepare Response messages (Commit phase)
- Validators produce & broadcast a new block after receiving enough Commit messages
The image below shows the 4 steps:
NODE RECOVERY / REGENERATION
If any node i fails and loses part of its history, thus, during its failure new logs were created such that its log is NOT up to date, the node executes the recovery event / operation.
The recovery event starts by attempting to restore from its local backup / cache. This is very efficient if the fault was caused by a hardware error. Once this is done, the node sends a <CHANGE_VIEW> message to other nodes. This prompts the other nodes to send node i a payload containing the up-to-date history required for the node to resume normal operations.
This payload includes: a replay of change view messages, PrepareRequest messages from past primaries, PrepareResponse messages and Commit messages.
With the above, it is possible for Node i to:
- restore itself to higher view
- restore itself to a view where Prepare Request is sent but not enough preparations to commit.
- restore itself to a view with Prepare Request sent and enough preparations to commit, consequently reaching CommitSent state;
- share commit signatures to a node that is committed (CommitSent flag activated).
DBFT v2.0 STATES
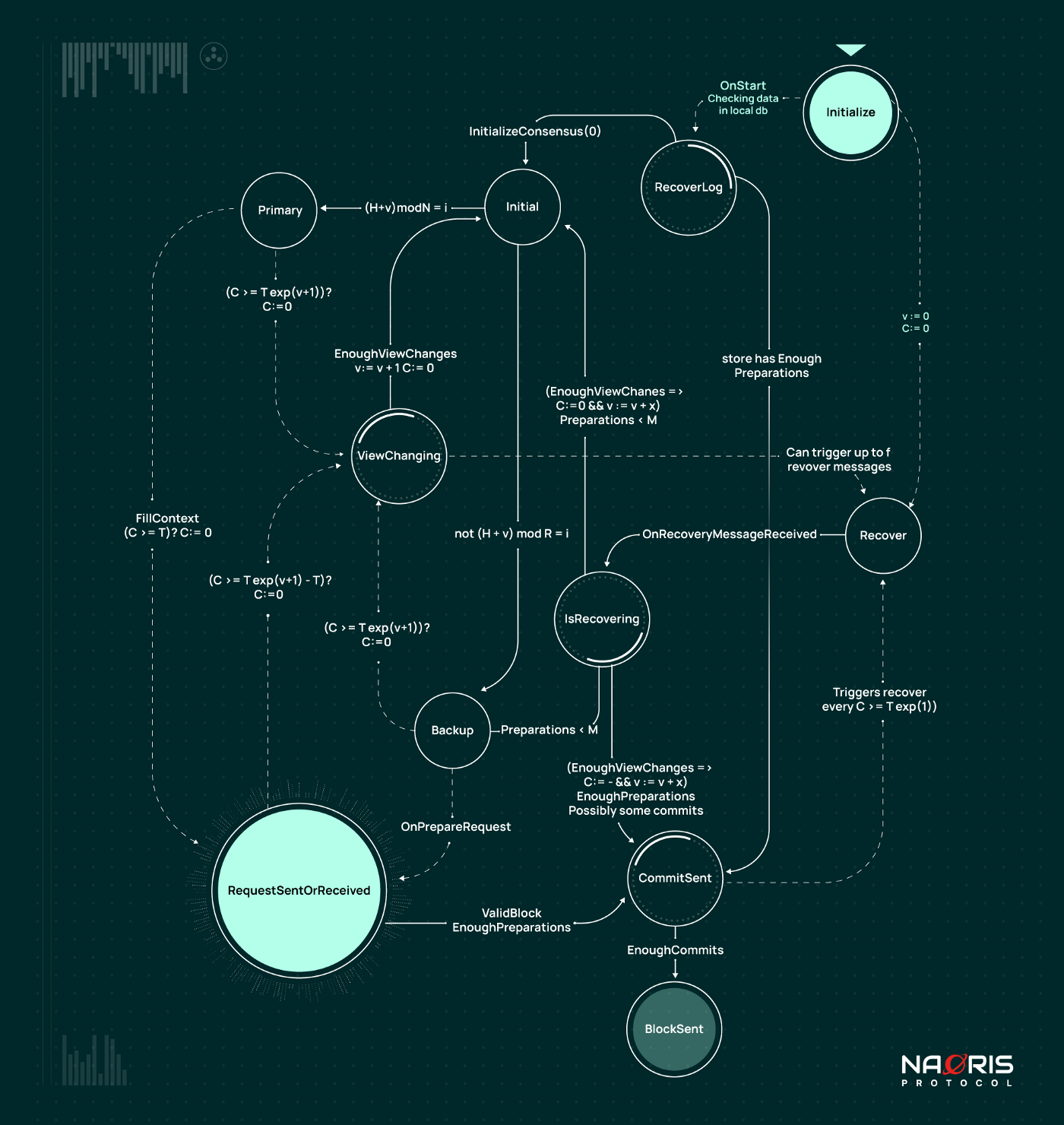
Looking from the top right corner of the image above, when a machine / node is initalized, it first checks for available data in the machine’s local db. If there is data available, the OnStart event is triggered. Otherwise, view is set to 0 (v := 0) and clock is reset (C := 0) and the machine is moved into the Recover state. From the Recover state, the node sends a Change_view request to the other nodes. It then waits to receive up to f recover messages. Recover payloads are sent by a maximum of f nodes that received the ChangeView request. N Nodes are currently selected based on the index of payload sender and local current view. Once it has received enough recovery messages (OnRecoveryMessageReceived), the node goes into the IsRecovering state. From this state, the node has 3 options:
1. It goes back to the Initial state if it has no information about the new view
2. It goes into the Backup state if it had some preparations before it went offline and needed to be recovered.
3. It goes straight into the CommitSent state if it has gone through enough view changes and is up to date, it has enough preparations (Prepare / PrepareResponse messages) and sometimes even some commits / replies. Enough preparations here specifically means M preparations where M is the number of honest nodes so M = N — f where f is the maximum number of faulty nodes. Remember f = (N — 1) / 3
From CommitSent state, a Block is finalized if enough commits are received. This is how the node in recovery rebuilds all blocks it missed during its fault.
On the other hand, after Onstart is triggered, the machine’s RecoverLog is checked since it has data in its local db. If the data store has Enough Preparations ( enough Prepare messages or PrepareResponse messages), the node moves into the CommitSent State. Otherwise consensus is Initialized and the node goes into the Initial State. From the Initial state, the node is either backup or primary. We already saw in the last episode what happens from this state.
It should be noticed that OnStart events trigger a ChangeView at view 0 in order to communicate to other nodes about its initial activity and its willingness to receive any Recover payload. The idea behind this is that a node that is starting late will probably find some advanced state already reached by the network.
EFFICIENCY, TIME AND SPACE COMPLEXITY
In terms of network communication:
- 1 message request from Client,
- n -1 Pre-prepare messages (or Prepare Request) from Primary node,
- n(n-1) Prepare messages (or Response) in entire system,
- n(n-1) Commit messages
- and n(n-1) create Block and Broadcast messages.
This brings the total to 1 + (n-1) + n(n-1) + n(n-1)+ n(n-1). This becomes 1 + n -1 + 3[n(n-1)]. So we get 1 + n-1+ 3[n²-n]. Then 1 + n-1+ 3n² — 3n. The final complexity is then 3n² — 2n.
The worst-case network bandwidth complexity of the entire system is therefore simplified as 3n² — 2n which in big-O notation is O(n²).
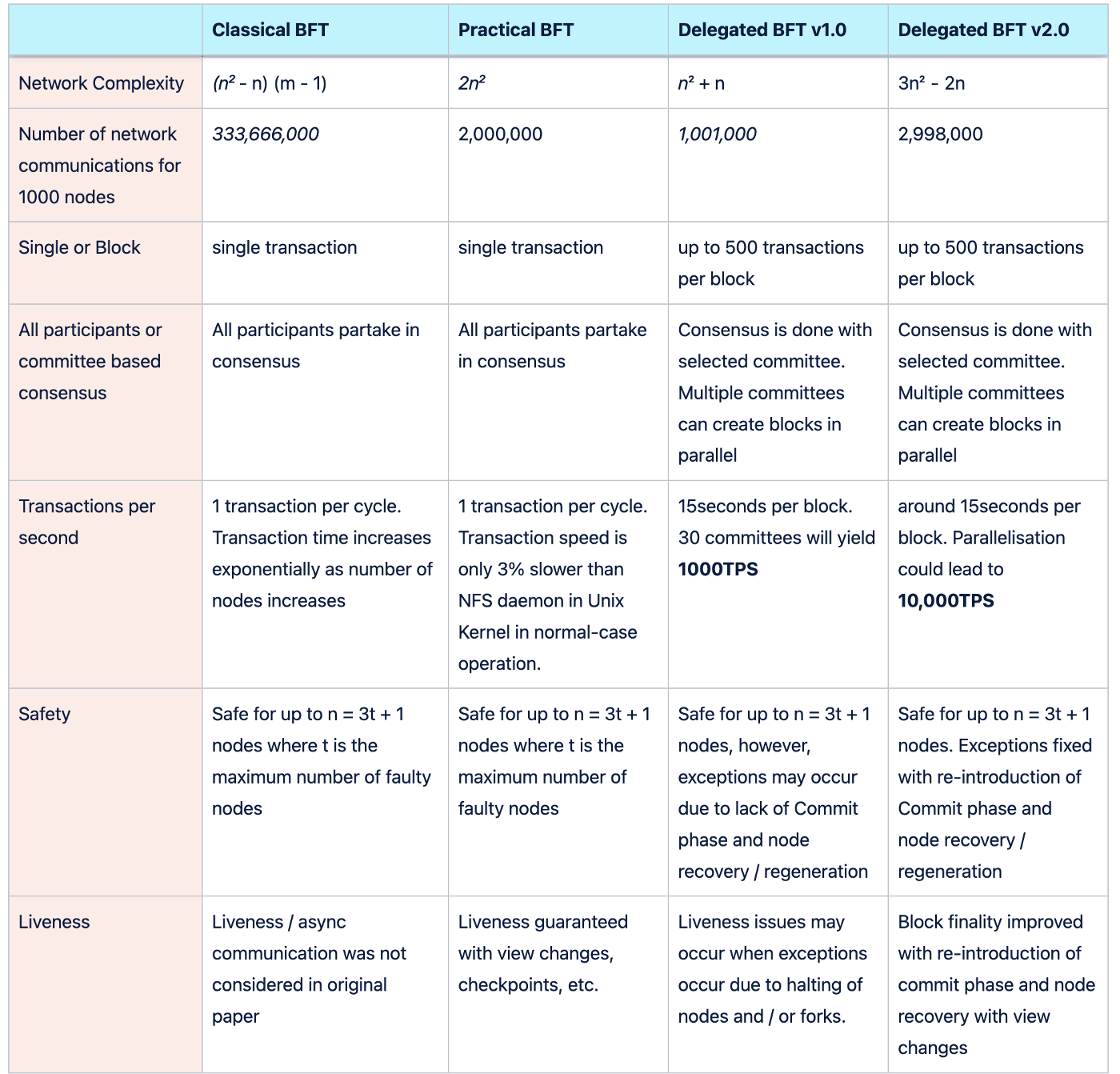
It would make sense to compare Classical BFTs, Practical BFTs, Delegated BFT v1.0 and Delegated BFT v2.0 at this point. The table below shows this comparison.
In terms of space complexity, let’s assume each node will have to spend x megabytes for storing any message / field. So (n * x)megabytes in total for views, another (n * x) megabytes for a pre-prepare message, (n² * x) megabytes for prepare messages, (n² * x) for commit messages and finally (n² * x) megabytes for create block and broadcast.
Therefore, the worst-case space complexity is x*(n + n +n² +n²+n²). This simplifies to [(3n² + 2n) * x] space consumed, thus, also O(n²).
Note that space complexity spikes significantly when node recovery / regeneration occurs due to the significant amount of payload transmitted for a node to resume normal operation.
CONCLUSION
To conclude this episode, let’s end with some of the core modifications between dBFT v1.0 and dBFT v2.0
- Reintroduction of the commit phase
- Regeneration mechanism able to recover failed nodes both in the local hardware and in the network P2P consensus layer.
- One block finality to the end-users and seed nodes;
- Avoid double exposure of block signatures by not allowing view changes after the Commit phase;
- Ability to propose blocks based on information shared through block headers (transactions are shared and stored in an independent synchronization mechanism);
In the next episode we will briefly touch on Federated Byzantine agreements and talk about Directed Acyclic Graphs. Catch you later!